Semi-Automated Cyber Threat Intelligence – ACT Platform v0.0.122 releases
Semi-Automated Cyber Threat Intelligence – ACT Platform
Semi-Automated Cyber Threat Intelligence (ACT) is a research project led by mnemonic as with contributions from the University of Oslo, NTNU, Norwegian Security Authority (NSM), KraftCERT and Nordic Financial CERT.
The main objective of the ACT project is to develop a platform for cyber threat intelligence to uncover cyber attacks, cyber espionage, and sabotage. The project will result in new methods for data enrichment and data analysis to enable identification of threat agents, their motives, resources, and attack methodologies. In addition, the project will develop new methods, work processes and mechanisms for creating and distributing threat intelligence and countermeasures to stop ongoing and prevent future attacks.
Architecture and Deployment Guide
The ACT platform is split into two layers, a REST layer which serves the REST API and a service back-end which implements the service logic and database access. The platform can be deployed either as a single node application where the REST layer and service back-end are combined in one application or as a scalable multi-node environment where the REST layer and service back-end are separated into multiple nodes each. The first approach is sufficient for test environments and is significantly easier to set up and maintain. For production environments – especially where a large amount of data is expected – the multi-node approach is preferable because it allows to easily scale up the platform when more processing power is needed and it offers redundancy in the case of node failures.
Single-Node Environment
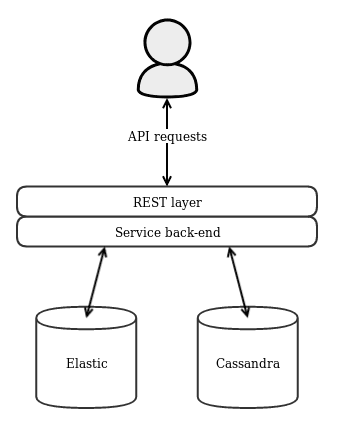
In such an environment only one single node containing both the REST layer and the service back-end is deployed and API requests are made directly towards this node. In addition, one Cassandraand one Elasticsearch cluster needs to be set up. The application uses Cassandra to store its data and Elasticsearch to search through it. In the single-node environment, it should suffice to only configure single-node Cassandra and Elasticsearch clusters. This is the bare minimum to get started with the ACT platform but it is neither fault-tolerant nor scalable.
Scalable Multi-Node Environment
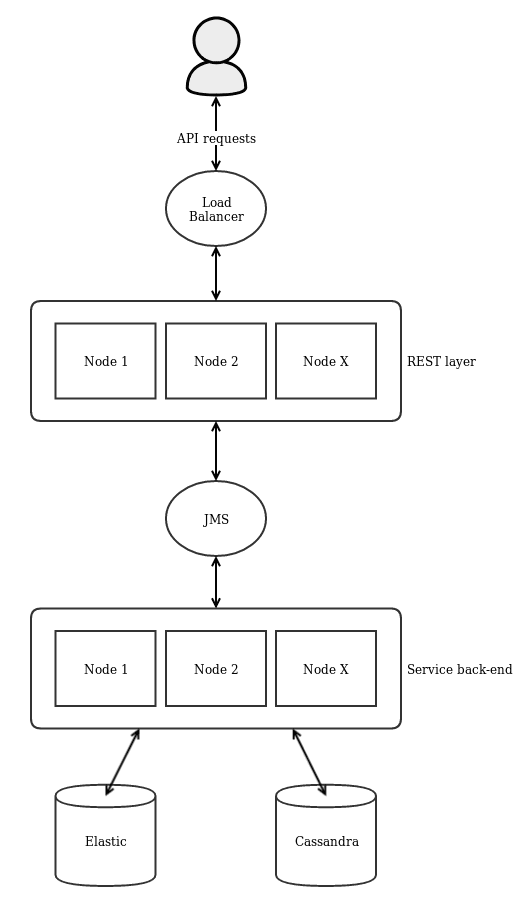
In a multi-node environment, the application is split into the two REST and service layers which are deployed separately and can be scaled up as needed. The two layers are connected using JMS which load balances requests from the REST layer across all available service nodes. Any JMS implementation should work but it is recommended to use ActiveMQ as the internal messaging implementation has been extensively tested with ActiveMQ. In front of the REST nodes, a load balancer such as the Apache HTTP Server or HAProxy should be installed which distributes the requests across all available REST nodes and are forwarded through JMS to the service nodes. Then API requests are made towards this load balancer. In this scenario, only the service nodes are directly connected to Cassandra and Elasticsearch. It is recommended to configure multi-node clusters for ActiveMQ, Cassandra, and Elasticsearch as well. If every deployment layer (REST -> JMS -> service -> database) is clustered the system becomes fault-tolerant and can be easily scaled up.
Deployment and Execution
The platform code contains three deployment modules, deployment-combined for the single node application, deployment-rest for the REST-only nodes and deployment-service for the service-only nodes. When the platform is compiled one tarball inside each deployment module will be created. Those tarballs contain everything (libraries, init script, example configurations, etc.) to execute the application. The application is configured using a properties file. See application.properties inside the examples folder of each deployment as an example. It is important that this configuration points to your Cassandra and Elasticsearch installations. In the multi-node environment, the connection to your ActiveMQ cluster must also be configured correctly and the configured message queue must be available in the cluster. Additionally, access control including users and organizations is defined in another properties file. See acl.properties as an example and the specification for more details. Make sure that your application configuration points to this properties file as well. The example access control configuration should be sufficient to test out the platform but should be adapted for production set-ups.
The bin folder of each deployment package contains an init script used to start and stop the application. Execute bin/init.sh start to start the platform and bin/init.sh stop to stop it again. The init script reads several environment variables in order to customize its behaviour:
- ACT_PLATFORM_CONFDIR: Directory where the configuration files are located (defaults to conf ).
- ACT_PLATFORM_LOGDIR: Directory where the log files are located (defaults to logs ).
- ACT_PLATFORM_JAVA_OPTS: Used to pass additional options to the Java process. Usually not required to be changed.
To quickly test the ACT platform simply extract the tarball from the deployment-combined/target folder and execute bin/init.sh start. On first start-up, the example configuration files from the examples folder will be copied into the configuration folder. Adjust the configuration to your needs, make sure that Cassandra and Elasticsearch are running and that the configuration points to them correctly. If everything is configured correctly running the init script will start up the whole application stack and the API server will start listening for requests on the port specified in the configuration. Check the log files for any error messages.
Install && Use
Copyright (c) 2017, mnemonic as <opensource@mnemonic.no>