diskover v2.2 releases: File system crawler, storage search engine and analytics
diskover
diskover is an open-source file system indexer that uses Elasticsearch to index and manage data across heterogeneous storage systems. Using diskover, you are able to more effectively search and organize files, and system administrators are able to manage storage infrastructure, efficiently provision storage, monitor and report on storage use, and effectively make decisions about new infrastructure purchases.
As the amount of file data generated by businesses continues to expand, the stress on expensive storage infrastructure, users and system administrators, and IT budgets continue to grow.
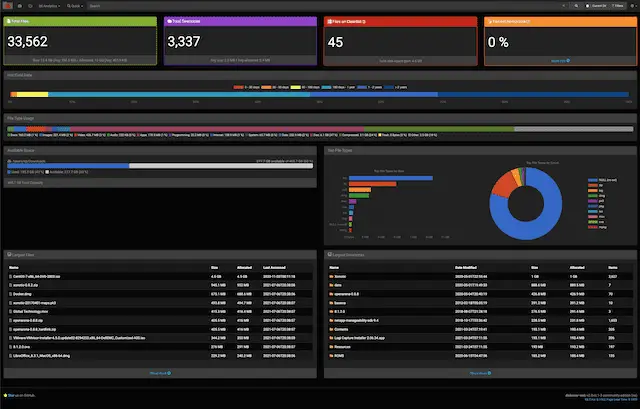
Using diskover, users can identify old and unused files and give better insights into data change, file duplication, and wasted space. It supports crawling local file systems, crawling NFS/SMB, cloud storage, etc. Plugins can be used for adding additional metadata.
It runs on Linux, macOS, and Windows 10 and is written in Python. Diskover’s web app, diskover-web, is written in PHP, Javascript, HTML5 and CSS.
Feature
Speed and Unique Scanning Architecture
With Elasticsearch as the backend search engine, Diskover is highly scalable and searches massive volumes of unstructured data instantaneously.
Unlike any others, Diskover scans all your data repositories in parallel, not serially, no matter where it lives, giving you immediate results in one global index.
Cost Analysis, Heatmap Report, and More
The cost analysis report and its granular configuration assists you with accurately charging your clients for data storage.
Another unique feature is Diskover’s heatmap analytical report allowing you to compare two indices from two different points in time. With this powerful tool, you can investigate data growth, shrinkage, and anomalies.
Diskover offers several other analytics, including repeatable queries.
Powerful Tools and Search Capabilities
Diskover enriches the indices with additional metadata and makes these attributes searchable, adding business and scheduling context, making it a perfect companion for file-based workflows.
With it’s smart tags system, auto-tagging, and tasks scheduler, Diskover makes it easy to curate your data in a safe and controlled environment, insuring you assets preservation.
Empowers All Stakeholders
Diskover allows all stakeholders to have their own relationship with data.
The clever views, file search tools, repeatable reports, and other smart features assist all lines of business users for in-depth analysis of data, informed decision making, as well as rigorous data management.
Reduce Your Operating Costs
Data findability combined with ease of sharing significantly improves the efficiency of the organization and its people.
Cost analysis tools and repeatable reports assist all stakeholders in making the right data-related decisions about time, resources, invoicing, and investments.
Boost Your File-Based Workflows
With its current features, Diskover enhances workflows and their monetization.
Stay tuned for an upcoming announcement that will take your file-based production line to the next level.
Changelog v2.2
fixed
- python error when scanning file/directory with invalid future timestamps causing scan to exit with critical error
added
- exception handling and logging for file/directory with invalid future timestamps, times are now set to 1970-01-01T00:00:00
Install & Use
Copyright 2017-2021 Diskover Data, Inc.