frontera v0.8.1: A scalable frontier for web crawlers
Frontera
Overview
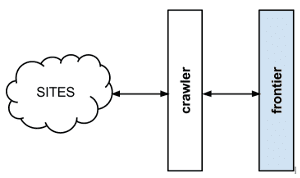
Frontera is a web crawling framework consisting of crawl frontier, and distribution/scaling primitives, allowing to build a large-scale online web crawler.
Frontera takes care of the logic and policies to follow during the crawl. It stores and prioritises links extracted by the crawler to decide which pages to visit next, and capable of doing it in the distributed manner.
Main features
- Online operation: small requests batches, with parsing, is done right after fetch.
- Pluggable backend architecture: low-level backend access logic is separated from crawling strategy.
- Two-run modes: single process and distributed.
- Built-in SqlAlchemy, Redis and HBase backends.
- Built-in Apache Kafka and ZeroMQ message buses.
- Built-in crawling strategies: breadth-first, depth-first, Discovery (with the support of robots.txt and sitemaps).
- Battle tested: our biggest deployment is 60 spiders/strategy workers delivering 50-60M of documents daily for 45 days, without downtime,
- Transparent data flow, allowing to integrate custom components easily using Kafka.
- Message bus abstraction, providing a way to implement your own transport (ZeroMQ and Kafka are available out of the box).
- Optional use of Scrapy for fetching and parsing.
- 3-clause BSD license, allowing to use in any commercial product.
- Python 3 support.
Changelog v0.8.1
- Some bugs are fixed due to dependencies update.
Installation
pip install frontera
Use
Copyright (c) Frontera developers