GitDorker v1.1.3 releases: scrape secrets from GitHub
GitDorker
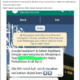
GitDorker is a tool that utilizes the GitHub Search API and an extensive list of GitHub dorks that I’ve compiled from various sources to provide an overview of sensitive information stored on github given a search query.
The Primary purpose of GitDorker is to provide the user with a clean and tailored attack surface to begin harvesting sensitive information on GitHub. GitDorker can be used with additional tools such as GitRob or Trufflehog on interesting repos or users discovered from GitDorker to produce the best results.
Rate Limits
GitDorker utilizes the GitHub Search API and is limited to 30 requests per minute. In order to prevent rate limits, a sleep function is built into GitDorker after every 30 requests to prevent search failures. Therefore, if one were to run use the alldorks.txt file with GitDorker, the process will take roughly 5 minutes to complete.
Requirements
** Python3
** GitHub Personal Access Token
git clone https://github.com/obheda12/GitDorker.git
** Install requirements inside of the requirements.txt file of this repo (pip3 install -r requirements.txt)
Please follow the guide below if you are unsure of how to create a personal access token.
Recommendations
It is recommended to provide GitDorker with at least two GitHub personal access tokens so that it may alternate between the two during the dorking process and reduce the likelihood of being rate limited. Using multiple tokens from separate GitHub accounts will provide the best results.
Dorks
Within the dorks folder is a list of dorks. It is recommended to use the “alldorks.txt” file when mapping out your github secrets attack surface. The “alldorks.txt” is my collection of dorks that I’ve pulled from various resources, totaling to 239 individual dorks of sensitive github information.
Usage
Below is an example of the results from running the query “tesla.com” with a small list of dorks.
The following command was run to query for “tesla.com” against a list of dorks:
python3 GitDorker.py -tf TOKENSFILE -q tesla.com -d dorks/DORKFILE -o tesla
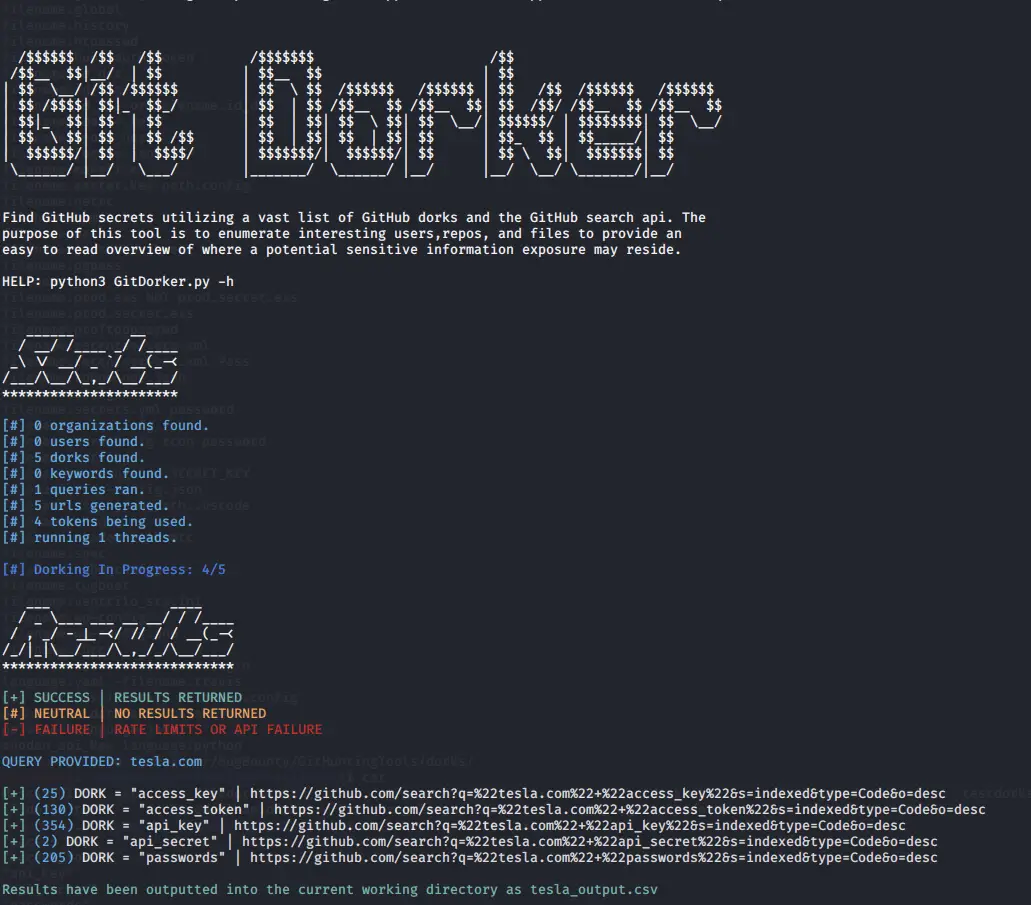
Note: The more advanced queries you put (i.e incorporation of the user, org, endpoint information, etc. the more succinct results you will achieve)
Tutorial
Source: https://github.com/obheda12/