Hamburglar: collect useful information from urls, directories, and files
The Hamburglar
Multithreaded and recursive directory scraping script. Stores useful information with the filepath and finding. All in one file, no external packages required!
The Hamburglar can find
- ipv4 addresses (public and local)
- emails
- private keys
- urls
- cryptocurrency addresses
Download
git clone https://github.com/needmorecowbell/Hamburglar.git
Use
python3 hamburglar.py -w -v -h path
Directory Traversal
- python3 hamburglar.py ~/Directory/
- This will recursively scan for files in the given directory, then analyzes each file for a variety of findings using regex filters
Single File Analysis
- python3 hamburglar.py ~/Directory/file.txt
- This will recursively scan for files in the given directory, then analyzes each file for a variety of findings using regex filters
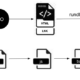
Web Request Mode
- python3 hamburglar.py -w https://google.com
- Adding a -w to hamburgler.py tells the script to handle the path as an url.
- Currently, this does not spider the page, it just analyzes the requested html content
Tips
- Adding -v will set the script into verbose mode, and -h will show details of available arguments
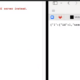
Example output:
Settings
- whitelistOn: turns on or off whitelist checking
- maxWorkers: number of worker threads to run concurrently when reading file stack
- whitelist: list of files or directories to exclusively scan for (if whitelistOn=True)
- blacklist: list of files, extensions, or directories to block in scan
- regexList: dictionary of regex filters with filter type as the key
Notes
- Inspiration came from needmorecowbell/sniff-paste, I wanted the same regex scraping but for every file in a given directory.
- Please contribute! If there’s an error let me know — even better if you can fix it 🙂
- Regex Contributions would be very helpful, and should be pretty easy to add!
- Please don’t use this project maliciously, it is meant to be an analysis tool