Photon v1.3.0 releases: extracts URLs, files, intel & endpoints from a target
Photon
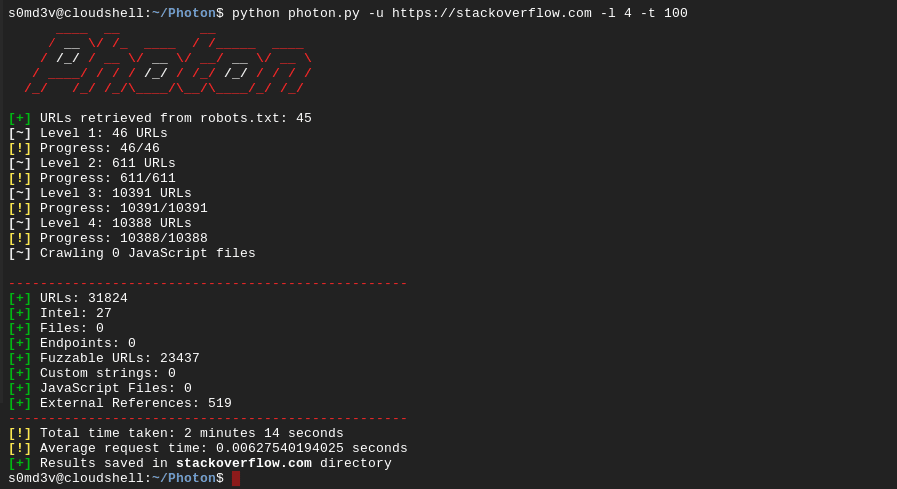
Photon is a lightning fast web crawler which extracts URLs, files, intel & endpoints from a target.
160 requests per second while extensive data extraction is just another day for Photon!
Main Features
The extensive range of options provided by Photon lets you crawl the web exactly the way you want, which is a cool thing on its own. However, the features of Photon that make it awesome are follows:
Data Extraction
Photon extracts the following data while crawling by default:
- URLs (in-scope & out-of-scope)
- URLs with parameters (
example.com/gallery.php?id=2) - Intel (emails, social media accounts, amazon buckets etc.)
- Files (pdf, png, xml etc.)
- JavaScript files & Endpoints present in them
- Strings based on custom regex pattern
The extracted information is saved in an organized manner.

Intelligent Multithreading
Here’s a secret, most of the tools floating on the internet aren’t properly multi-threaded even if they are supposed to. They either supply a list of items to threads which results in multiple threads accessing the same item or they simply put a thread lock and end up rendering multi-threading useless.
But Photon is different or should I say “genius”? Take a look at this and decide yourself.
Ninja Mode
In Ninja Mode, 3 online services are used to make requests to the target on your behalf.
So basically, now you have 4 clients making requests to the same server simultaneously which gives you a speed boost if you have a slow connection, minimizes the risk of connection reset as well as delays requests from a single client.
Here’s a comparison generated by Quark where the lines represent threads:

Plugins
Photon’s capabilites can be further extended by using plugins.
Available plugins:
- dnsdumpster: Generates an image containing the DNS data of the target domain.
- Exporter: Plugin to export results in JSON, support for more formats is being worked on.
Plugins in active development:
- Quark: A plugin to plot a graph making it easier to inspect relationships between different webpages using Quark.
- XSStrike: Modular & targeted version of XSStrike to be used with Photon.
- dnsdumpster: A new version of the plugin is in development which will save the DNS data in a nicely formatted HTML file.
Changelog
v1.3.0
- Dropped Python < 3.2 support
- Removed Ninja mode
- Fixed a bug in link parsing
- Fixed Unicode output
- Fixed a bug which caused URLs to be treated as files
- Intel is now associated with the URL where it was found
Download
git clone https://github.com/s0md3v/Photon.git
Usage
-u –url
Specifies the URL to crawl.
python photon.py -u http://example.com
-l –level
It specifies how much deeper should photon crawl.
python photon.py -u http://example.com -l 3
Default Value: 2
-d –delay
It specifies the delay between requests.
python photon.py -u http://example.com -d 1
Default Value: 0
-t –threads
The number of threads to use.
python photon.py -u http://example.com -t 10
Default Value: 2
Note: The optimal number of threads depends on your connection speed as well as the nature of the target server. If you have a decent network connection and the server doesn’t have any rate limiting in place, you can use up to 100 threads.
-c –cookie
Cookie to send.
python photon.py -u http://example.com -c "PHPSSID=821b32d21"
-n –ninja
Toggles Ninja Mode on/off.
python photon.py -u http://example.com --ninja
Default Value: False
-s –seeds
Lets you add custom seeds, separated by commas.
python photon -u http://example.com -s “http://example.com/portals.html,http://example.com/blog/2018”
Copyright (C) 2018 s0md3v
Source: https://github.com/s0md3v/