Universal Reddit Scraper v3.4 releases: Scrape Subreddits, Redditors, and comments on posts
Universal Reddit Scraper
This is a universal Reddit scraper that can scrape Subreddits, Redditors, and comments on posts.
Scrape speeds will be determined by the speed of your internet connection.
A Table of All Subreddit, Redditor, and Post Comments Attributes
These attributes will be included in each scrape.
| Subreddits | Redditors | Post Comments |
|---|---|---|
| Title | Name | Parent ID |
| Flair | Fullname | Comment ID |
| Date Created | ID | Author |
| Upvotes | Date Created | Date Created |
| Upvote Ratio | Comment Karma | Upvotes |
| ID | Link Karma | Text |
| Is Locked? | Is Employee? | Edited? |
| NSFW? | Is Friend? | Is Submitter? |
| Is Spoiler? | Is Mod? | Stickied? |
| Stickied? | Is Gold? | |
| URL | Submissions* | |
| Comment Count | Comments* | |
| Text | Hot* | |
| New* | ||
| Controversial* | ||
| Top* | ||
| Upvoted* (may be forbidden) | ||
| Downvoted* (may be forbidden) | ||
| Gilded* | ||
| Gildings* (may be forbidden) | ||
| Hidden* (may be forbidden) | ||
| Saved* (may be forbidden) |
* Includes additional attributes; see Redditors section for more information
Subreddits
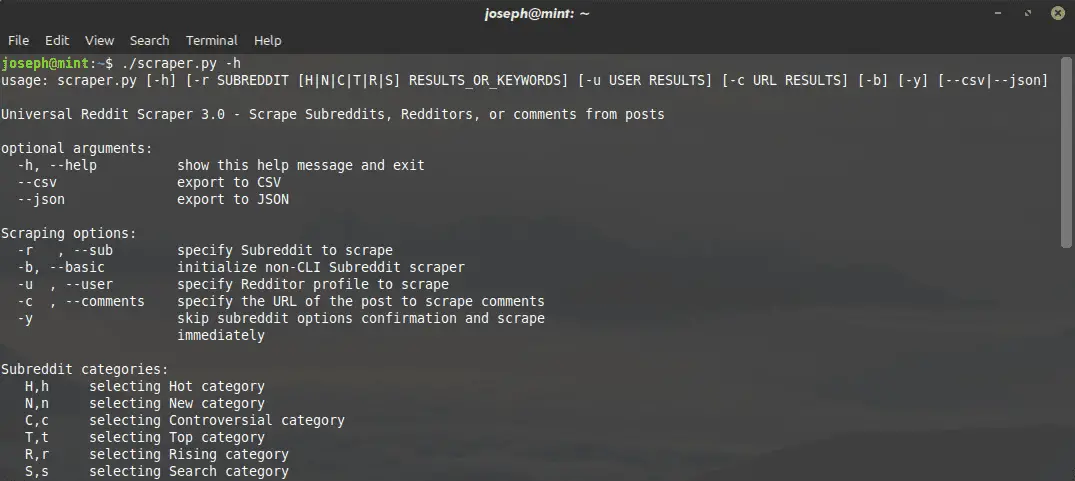
$ ./scraper.py -r SUBREDDIT [H|N|C|T|R|S] N_RESULTS_OR_KEYWORDS –FILE_FORMAT
You can specify Subreddits, which category of posts, and how many results are returned from each scrape. I have also added a search option where you can search for keyword(s) within a Subreddit and the scraper will get all posts that are returned from the search.
These are the post category options:
- Hot
- New
- Controversial
- Top
- Rising
- Search
NOTE: All results are returned if you search for something within a Subreddit, so you will not be able to specify how many results to keep.
Once you configure the settings for the scrape, the program will save the results to either a .csv or .json file.
The file names will follow this format: “r-SUBREDDIT-POST_CATEGORY DATE.[FILE_FORMAT]”
If you have searched for keywords in a Subreddit, file names are formatted as such: “r-SUBREDDIT-Search-‘KEYWORDS’ DATE.[FILE_FORMAT]”
Redditors
$ ./scraper.py -u USER N_RESULTS –FILE_FORMAT
You can also scrape Redditor profiles and specify how many results are returned.
Of these Redditor attributes, the following will include additional attributes:
| Submissions, Hot, New, Controversial, Top, Upvoted, Downvoted, Gilded, Gildings, Hidden, and Saved | Comments |
|---|---|
| Title | Date Created |
| Date Created | Score |
| Upvotes | Text |
| Upvote Ratio | Parent ID |
| ID | Link ID |
| NSFW? | Edited? |
| Text | Stickied? |
| Replying to (title of post or comment) | |
| In Subreddit (Subreddit name) |
NOTE: If you are not allowed to access a Redditor’s lists, PRAW will raise a 403 HTTP Forbidden exception and the program will just append a “FORBIDDEN” underneath that section in the exported file.
NOTE: The number of results returned will be applied to all attributes. I have not implemented code to allow users to specify different numbers of results returned for individual attributes.
The file names will follow this format: “u-USERNAME DATE.[FILE_FORMAT]”
Post Comments
$ ./scraper.py -c URL N_RESULTS –FILE_FORMAT
These scrapes were designed to be used with JSON only. Exporting to CSV is not recommended, but it will still work.
You can also scrape comments from posts and specify the number of results returned.
Comments scraping can either return structured JSON data down to third-level comment replies, or you can simply return a raw list of all comments with no structure.
To return a raw list of all comments, specify 0 results to be returned from the scrape.
When exporting raw comments, all top-level comments are listed first, followed by second-level, third-level, etc.
NOTE: You cannot specify the number of raw comments returned. The program with scrape all comments from the post, which may take a while depending on the post’s popularity.
The file names will follow this format: “c-POST_TITLE DATE.[FILE_FORMAT]”
Changelog v3.4
Added
taisun– A Python module written in Rust that contains the depth-first search algorithm and associated data structures for structured comments scraping. This library will eventually contain additional code that handles compute-heavy tasks.- GitHub Actions Workflows
rust.yml– Format and lint Rust code.python.yml– Format and test Python code.manual.yml– Build and deploy themdBookmanual to GitHub Pages.
- A new user guide/manual built from
mdBook. - Added type hints to all
urs/code.
Changed
- Dates used in this program have been updated to use the ISO8601 timestamp format (
YYYY-MM-DD HH:MM:SS). - Docstrings have been updated from NumPy to reStructuredText format.
- Simplifying the
STYLE_GUIDE.md– The style is dictated byBlackandisortfor Python code, andrustfmtfor Rust. - Simplifying the
README.md- Most information previously listed there has been moved to the user guide/manual.
- Formatted every single Python file with
Blackandisort. - Upgraded/recorded new demo GIFs.
Tutorial
Copyright (c) 2020 Joseph Lai
Suggested Reading: