yarGen
What does yarGen do?
yarGen is a generator for YARA rules
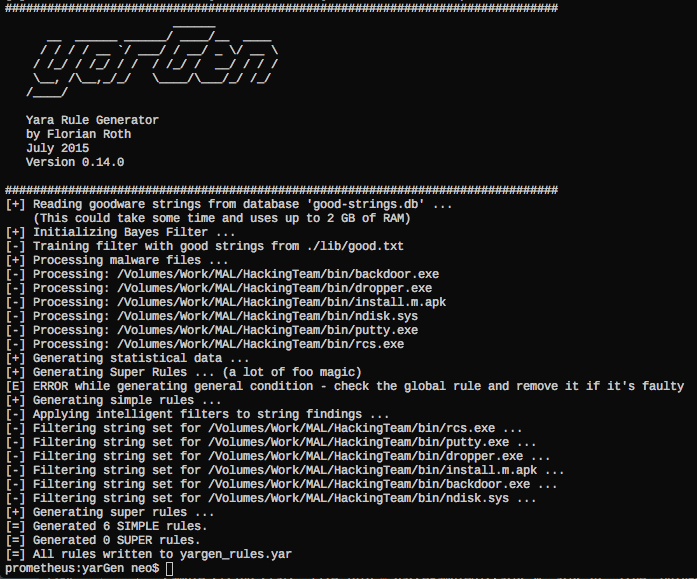
The main principle is the creation of Yara rules from strings found in malware files while removing all strings that also appear in goodware files. Therefore yarGen includes a big goodware strings and opcode database as ZIP archives that have to be extracted before the first use.
The rule generation process also tries to identify similarities between the files that get analyzed and then combines the strings to so-called super rules. The super rule generation does not remove the simple rule for the files that have been combined in a single super rule. This means that there is some redundancy when super rules are created. You can suppress a simple rule for a file that was already covered by super rule by using –nosimple.
Changelog v0.23.4
- fix: broken super rule generation
Installation
- Make sure you have at least 4GB of RAM on the machine you plan to use yarGen (8GB if opcodes are included in rule generation, use with –opcodes)
- Download the latest release from the “release” section
- Install all dependencies with sudo pip install scandir lxml naiveBayesClassifier pefile (@twpDone reported that in case of errors try sudo pip install pefile and sudo pip install scandir lxml naiveBayesClassifier)
- Run python yarGen.py –update to automatically download the built-in databases. They are saved into the ‘./dbs’ subfolder. (Download: 913 MB)
- See help with python yarGen.py –help for more information on the command line parameters
Memory Requirements
Warning: yarGen pulls the whole goodstring database to memory and uses at least 3 GB of memory for a few seconds – 6 GB if opcodes evaluation is activated (–opcodes).
I’ve already tried to migrate the database to sqlite but the numerous string comparisons and lookups made the analysis painfully slow.
Command Line Parameters
usage: yarGen.py [-h] [-m M] [-y min-size] [-z min-score] [-x high-scoring]
[-s max-size] [-rc maxstrings] [--excludegood]
[-o output_rule_file] [-a author] [-r ref] [-l lic]
[-p prefix] [--score] [--nosimple] [--nomagic] [--nofilesize]
[-fm FM] [--globalrule] [--nosuper] [--update] [-g G] [-u]
[-c] [-i I] [--nr] [--oe] [-fs size-in-MB] [--noextras]
[--debug] [--opcodes] [-n opcode-num]
yarGen
optional arguments:
-h, --help show this help message and exit
Rule Creation:
-m M Path to scan for malware
-y min-size Minimum string length to consider (default=8)
-z min-score Minimum score to consider (default=5)
-x high-scoring Score required to set string as 'highly specific
string' (default: 30)
-s max-size Maximum length to consider (default=128)
-rc maxstrings Maximum number of strings per rule (default=20,
intelligent filtering will be applied)
--excludegood Force the exclude all goodware strings
Rule Output:
-o output_rule_file Output rule file
-a author Author Name
-r ref Reference
-l lic License
-p prefix Prefix for the rule description
--score Show the string scores as comments in the rules
--nosimple Skip simple rule creation for files included in super
rules
--nomagic Don't include the magic header condition statement
--nofilesize Don't include the filesize condition statement
-fm FM Multiplier for the maximum 'filesize' condition value
(default: 3)
--globalrule Create global rules (improved rule set speed)
--nosuper Don't try to create super rules that match against
various files
Database Operations:
--update Update the local strings and opcodes dbs from the
online repository
-g G Path to scan for goodware (dont use the database
shipped with yaraGen)
-u Update local standard goodware database with a new
analysis result (used with -g)
-c Create new local goodware database (use with -g and
optionally -i "identifier")
-i I Specify an identifier for the newly created databases
(good-strings-identifier.db, good-opcodes-
identifier.db)
General Options:
--nr Do not recursively scan directories
--oe Only scan executable extensions EXE, DLL, ASP, JSP,
PHP, BIN, INFECTED
-fs size-in-MB Max file size in MB to analyze (default=10)
--noextras Don't use extras like Imphash or PE header specifics
--debug Debug output
Other Features:
--opcodes Do use the OpCode feature (use this if not enough high
scoring strings can be found)
-n opcode-num Number of opcodes to add if not enough high scoring
string could be found (default=3)
Best Practice
See the following blog posts for a more detailed description of how to use yarGen for YARA rule creation:
How to Write Simple but Sound Yara Rules – Part 1
How to Write Simple but Sound Yara Rules – Part 2
How to Write Simple but Sound Yara Rules – Part 3
yarGen – Yara Rule Generator, Copyright (c) 2015, Florian Roth
All rights reserved.