
Photo by XPS on Unsplash
Currently, Database security is a must. If you failed to do so, it will lead to major business loss. If the system architecture is large and the database is huge, then you must take major safety precautions. So before starting, you must choose an appropriate database, and its not an easy task. Before finalizing a DB for your system, you need to check for it’s pros and cons. In most cases, PostgreSQL is the best choice.
PostgreSQL, also known as Postgres or PG, is a free and open-source relational database management system based on SQL. It supports transactions with Atomicity, Consistency, Isolation, Durability (ACID) properties. It can handle complex and big queries very efficiently. It is supported by single machines and data warehouses. It is compatible with macOS, Windows, Linux, FreeBSD, and OpenBSD. There are no big differences between PostgreSQL and other DBs, but some of its features are still worth looking into.
Performance
Needless to say, PostgreSQL is much faster than other SQL databases:
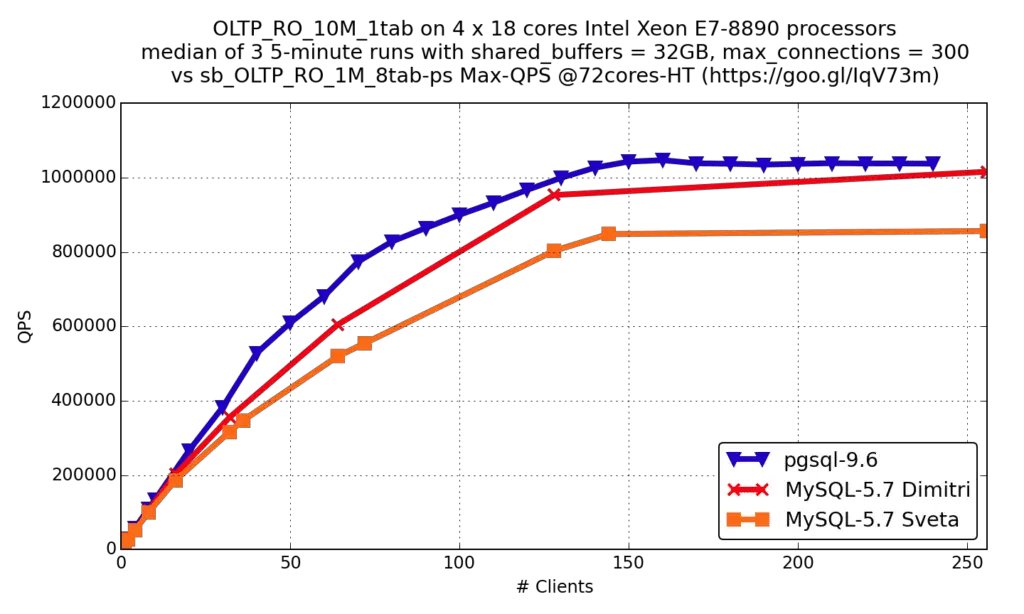
Postgres 13’s performance enhancements include both built-in configurations and heuristics, which make your database run smoothly out of the box. Its additional features give you more flexibility in expanding your schema and queries. In Postgres 13, there are B-Tree indexes that mainly help you remove duplicated entries. PostgreSQL can handle de-duped entries, which indirectly makes indexes smaller. You can use PG de-duped features from 13 onwards. You just need to handle deduplicate_items storage params. Here’s an example:

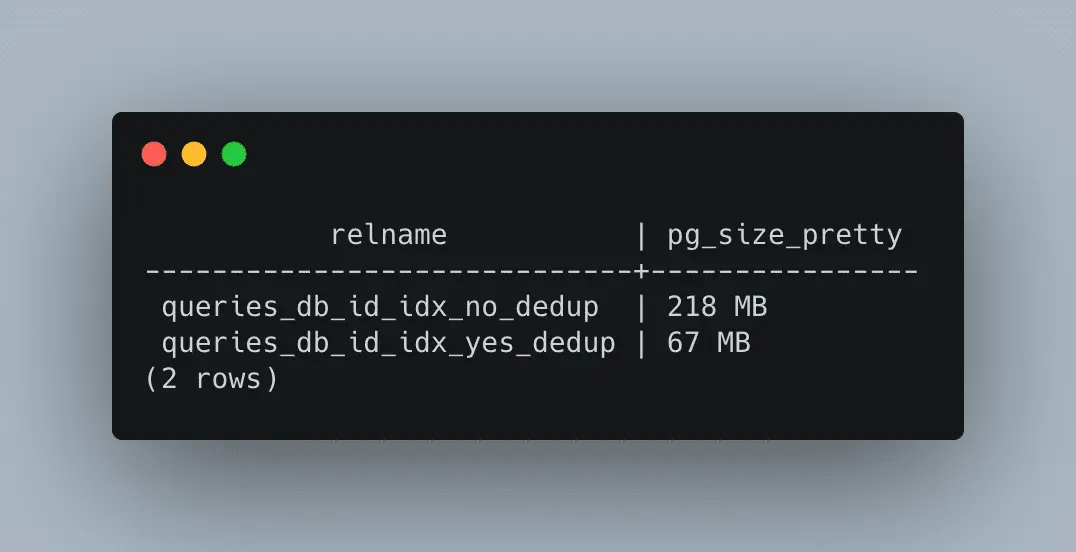
As you can see, once we remove duplicate data, the size drastically gets 3 times smaller. Reducing the size of the indexes helps boost performance. Thus, complex query results come faster.
Sharding
Sharding is a natural way to split and store data in multiple databases, with or without built-in support. It’s basically separating your data into multiple data processes, usually on different servers. This means more storage capacity, more CPU power, and so on.
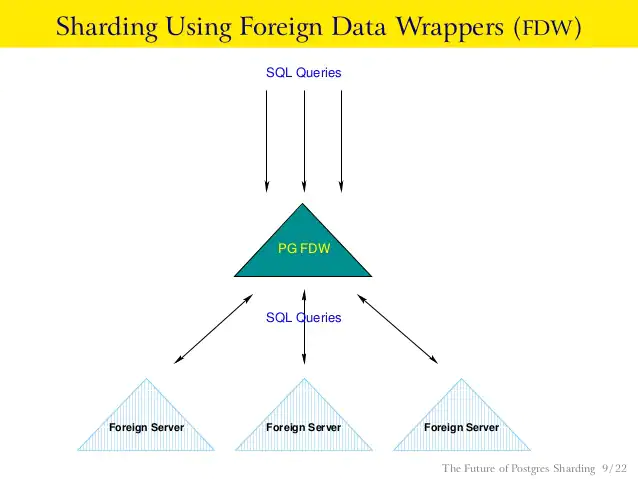
Standard apps have only big data sets, so there arises a need for sharding. You can start by splitting these data sets and then distributing those components into a bunch of servers. If you have more than one app, it is usually a good idea to keep data information outside of your app. Data management becomes an issue when you start getting a lot of data, so it’s better to arrange it from the beginning.
In the initial days, it was not possible to shard in PG. However, due to wide community support, it’s simple and easy to do now. In PG, sharding can be done with foreign data wrappers (FDW). Let’s understand how to use FDW with an example:
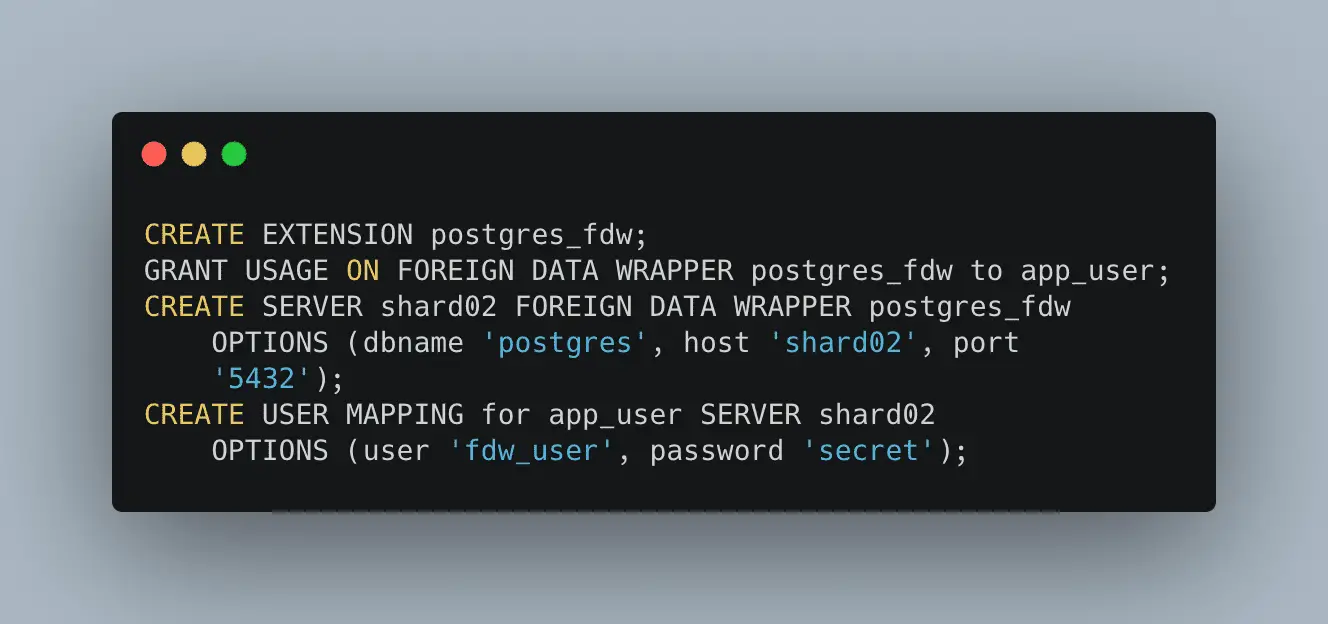
We need sharding in two cases mainly:
- When, after splitting the table, the amount of data is too large or too complex to be processed by a single server
- In use cases where data in a large table can be split into two or more components that can benefit most search patterns, like in the case of geographically distributed users
Schema Optimizations
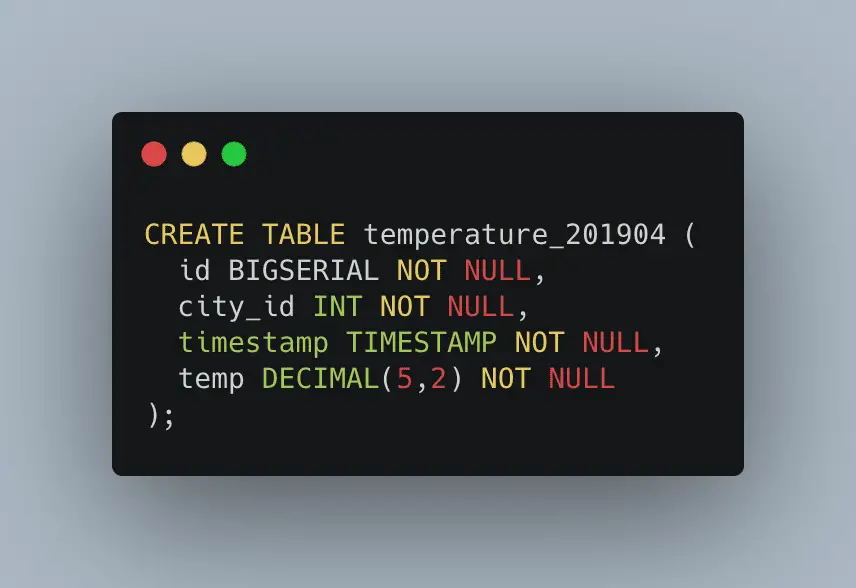
PostgreSQL table partition provides options to convert one table into several tables and have one table appear in your application. It might affect the performance, so do proper research before you start.
Let’s take an example to understand this better. You have one column called dateTime, which will store the created_at value of a record. Your initial requirement is to store data for the current thirty days only. So, to simplify the task, create a separate partition for each day. There will be 30 partitions as per your requirement. When the final policy is enforced, you can simply use DROP TABLE to remove a single, separated table from the database rather than attempt to remove the targeted table from the entire table. By doing so, you can avoid lots of database operations.
Let’s take another example. Let’s say you have a table with two data columns, big_data and int_data. Data stored in big_data is typically one kilobyte per record, and int_data is updated several times. Therefore, all int_data updates will cause big_data to be copied as well. Because these data columns are integrated, updates will create more spilled space, 1kb sequence per update.
The best approach to deal with such situations is to split the int_data into a different table. When you update it to that separate table, no big_data duplicates will be generated. However, remember that separating these columns means you will need to use JOIN to access both tables. It may not be advisable, depending on your use case.
Monitoring
Always monitor the database. PostgreSQL automatically logs a number of activities but still needs to focus on some key parts. PostgreSQL 13 can have a provision of WAL, which helps you log query stats.
WAL means write-ahead log. It helps you determine crashes or other activities. Example of WAL:

Apart from that, you can use log_min_duration_statement, which is useful for understanding slow queries. In PostgreSQL 13, they introduced log_min_duration_sample, which brings some flexibility to logs.
Database Upgrades
Major version updating in PostgreSQL requires re-writing data. It’s not an easy task to like OS updates. You need to take care of all your existing data and data types. Sometimes updating requires data to be re-written in a new data type.
There are two ways through PostgreSQL can be updated. The first is with pg_update. This is a tool, which converts data from the old to the new format. A major drawback of this is that it requires a database to go offline. This is not possible if your system is live with millions of users.
The second way is to use logical replication. Logical replication means there’s a replica of the existing server used for hot standby. To begin with logical replication, first, check the official PostgreSQL manual. It’s a three-step process:
- Set up a new server with an upgraded version of PostgreSQL
- Set up logical replication on a new server.
- Switch to the hot standby and cut the old one. For achieving the same, you can use existing tools as well.
If it’s a minor update, you can update it like OS. Just update the PostgreSQL binary and restart the server. It will quickly process, so it won’t affect existing DBs and users.
Conclusion
The major benefit you can get from using PostgreSQL as the main DB is that you can optimize performance. It is a good choice if you want to secure and optimize your data. The community is very large and has a great track record when it comes to updates and long–term planning.
