CloudScraper: enumerate targets in search of cloud resources
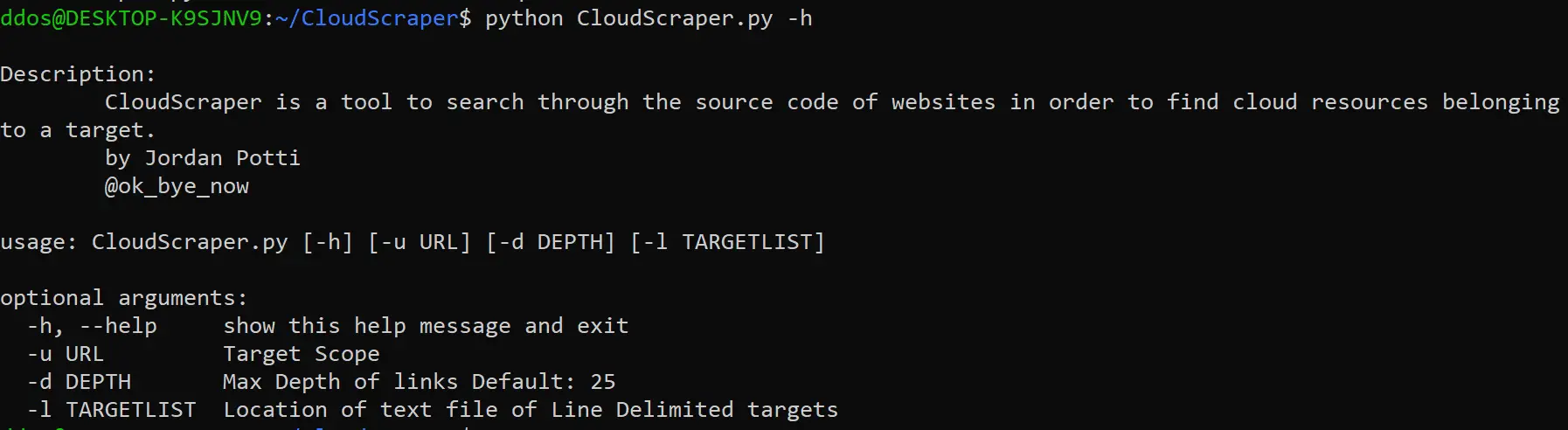
CloudScraper is a Tool to spider and scrape targets in search of cloud resources. Plug in a URL and it will spider and search the source of spidered pages for strings such as ‘s3.amazonaws.com’, ‘windows.net’ and ‘digitaloceanspaces’. AWS, Azure, Digital Ocean resources are currently supported.
This tool was inspired by a recent talk by Bryce Kunz. The talk Blue Cloud of Death: Red Teaming Azure takes us through some of the lesser known common information disclosures outside of the ever common S3 Buckets.
The benefit of using raw regex’s instead of parsing for href links is that many times, these are not included in href links, they can be buried in JS or other various locations. CloudScraper grabs the entire page and uses a regex to look for links. This also has its flaws such as grabbing too much or too little but at least we know we are covering our bases 🙂
Download
git clone https://github.com/jordanpotti/CloudScraper.git
Use
Copyright (c) 2018 JP
Source: https://github.com/jordanpotti/





