When computer vision algorithms like Convolutional Neural Networks (CNNs), Autoencoders, and Feature Detection and Matching are used to process and extract meaningful information from visual data such as videos and images, computer vision data is birthed.
The resulting data is applicable in priceless industrial applications like autonomous vehicles, object detection, facial recognition, and image recognition.
However, dealing with the storage and management of large volumes of computer vision data has its challenges. This article highlights these challenges, practical solutions, and the value of ReductStore in handling computer vision data.
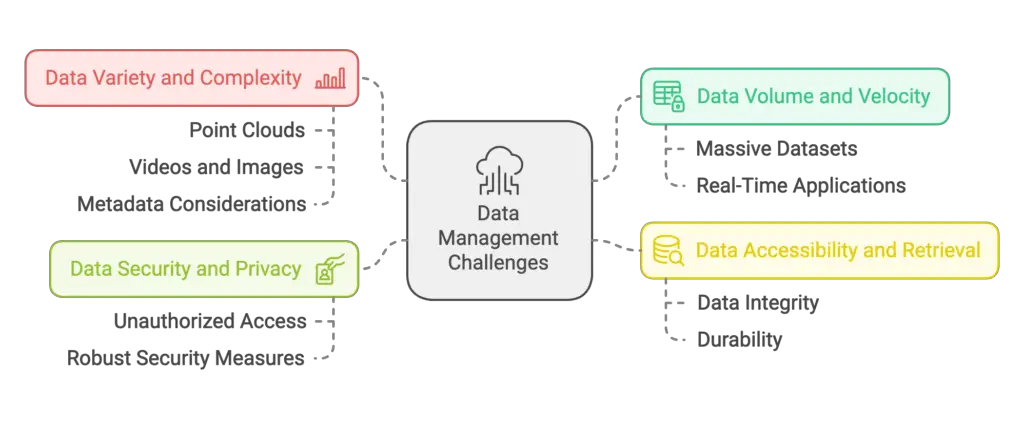
Challenges:
- Data Volume and Velocity: To effectively train computer vision models, one requires massive datasets. Also, the constant data stream generated by real-time applications requires prompt storage and processing.
- Data Variety and Complexity: Data exists in diverse formats like point clouds, videos, and images that vary in frame rates and resolutions. Additionally, each data point associated with metadata like labels, location, and timestamp are a non-optional consideration.
- Data Accessibility and Retrieval: Over time, data integrity and durability needs to be measured on the basis of how efficient is the retrieval mechanism of specific data points in regards to criteria like location and time.
- Data Security and Privacy: Sensitive data should be safe from unauthorized access through the implementation of robust security measures that neutralize data breaches.
Known Practical Strategies for Storing Computer Vision Data:
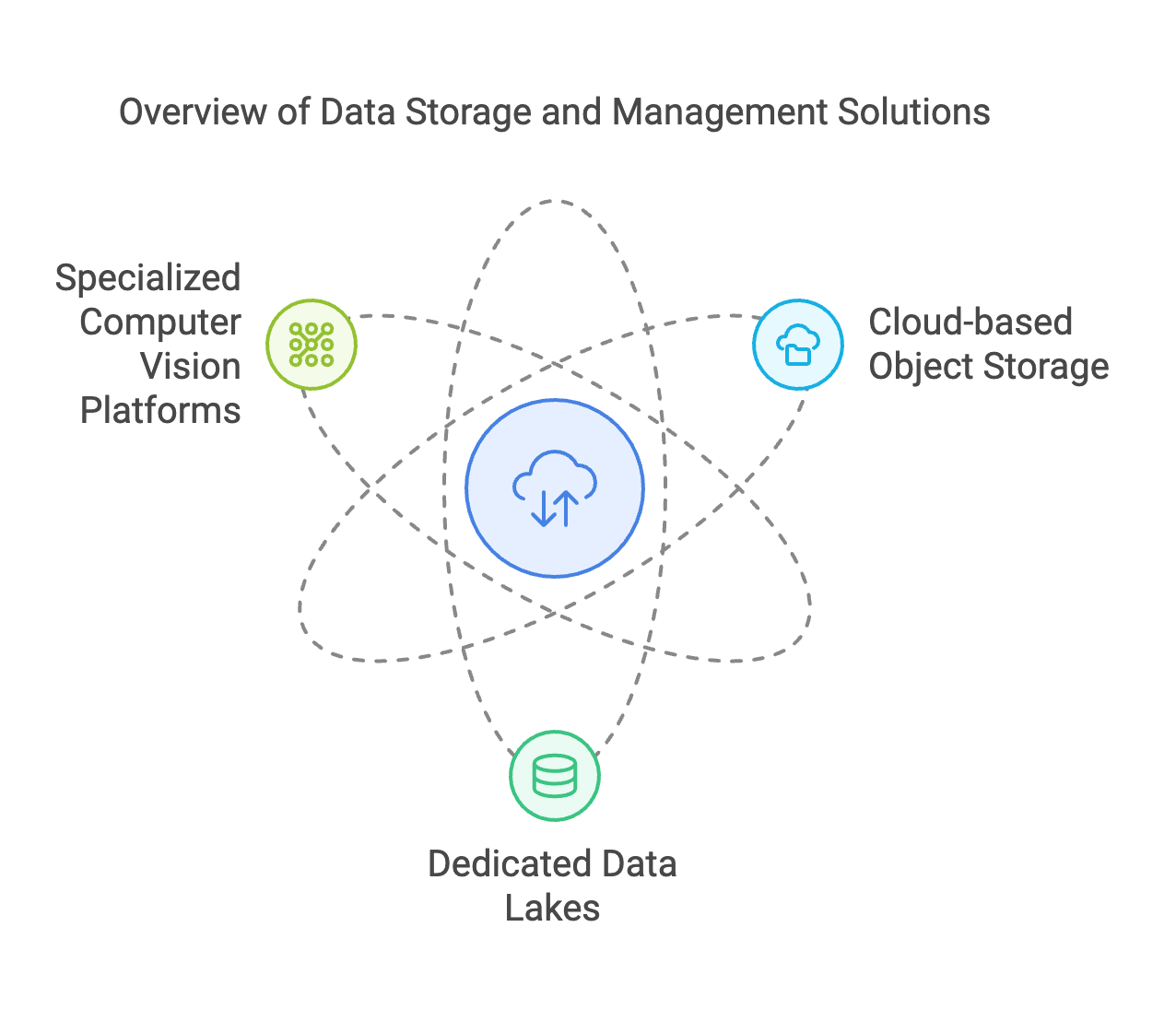
The challenges arising from handling the storage of computer vision data can be addressed by the following effective industrial storage strategies:
- Cloud-based object storage: Solutions like Amazon S3 and Google Cloud Storage offer highly durable and scalable storage for images and videos data. Azure Blob Storage encompasses various storage tiers depending on the needed performance and cost requirement. These solutions are easy to scale (storage capacity), durable due to built-in redundancy, secure through encryptions and access control, and seamlessly integrate with other cloud services.
- Dedicated Data Lakes: Solutions like Hadoop Distributed File System (HDFS), Apache Parquet, and Apache ORC are scalable in handling large data sets, flexible through their support for various query patterns and data formats, and cost-effective due to on-premise deployment support.
- Specialized Computer Vision Data Platforms: Solutions like Clarifai not only support storage and management of training data but also provide the means to build, train, and deploy custom computer vision models. When data labeling and annotation are a requirement, a solution like LabelBox takes the center stage (often collaborating with object storage solutions).
Why ReductStore?
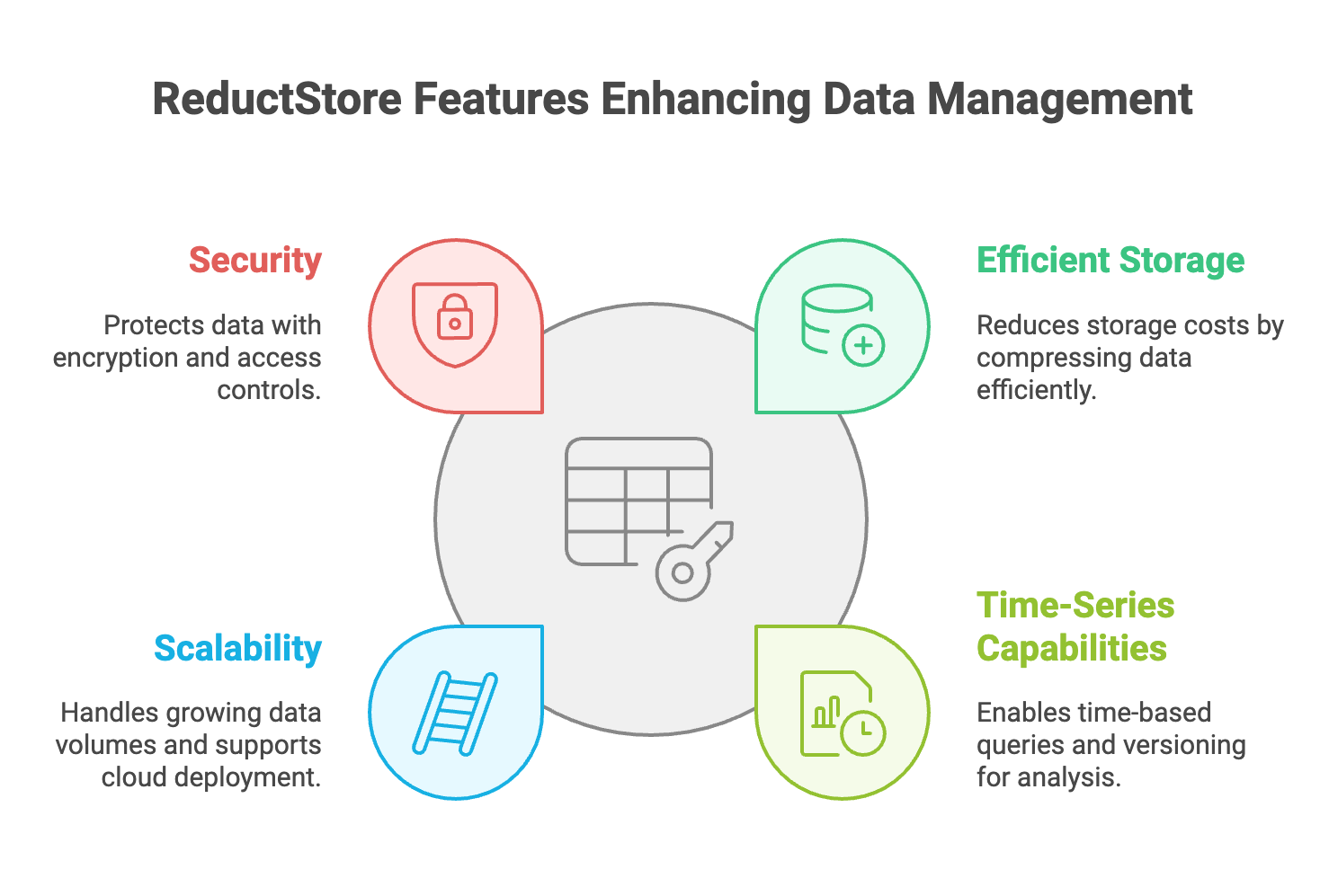
When it comes to the storage and management of computer vision data, the time-series object store attribute of ReductStore offers several advantages:
- Efficient Storage: You do not have to worry about storage costs as it notably reduces due to ReductStore ability to significantly compress data. In regards to the storage of large objects like videos and images, ReductStore is perfectly optimized for such needs.
- Time-Series Capabilities: Time-based queries and analysis are valid through timestamping as each video or image is timestamped on arrival. Also, the storage and retrieval of multiple image versions is possible as versioning helps in model training and tracking changes.
- Scalability: ReductStore is able to handle increasing data volumes due to its horizontal scaling attribute. Also, if high availability or easy scaling is among your ReductStore requirements, you can deploy it on a cloud platform of your preference.
- Security: Through its flexible encryption measures, data security is attained whether data is in transit or at rest. Sensitive data protection implementation is possible through granular access control.
ReductStore for Computer Vision Data Storage
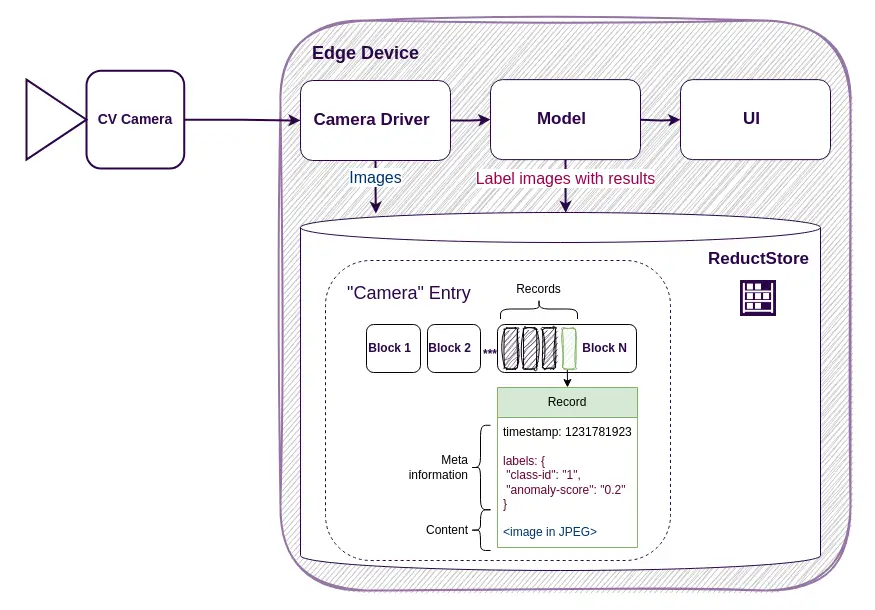
To highlight the effectiveness of ReductStore in handling computer vision data, consider the following:
- Data Collection and Prepossessing: You can either collect real-world data from sources like web scrapping or cameras, generate synthetic data via StyleGAN or SimCLR tools, or use preprocessing techniques like augmentation, normalization, and resizing.
- Data Storage in ReductStore: Each data sample is assigned a timestamp and organized into batches for storage and retrieval efficiency. Each stored data is attributed with relevant metadata like source, format, and image resolution.
- Data Retrieval and Analysis: ReductStore’s API permits efficient retrieval of data based on criteria like timestamps. The retrieved data undergoes analysis via tools like OpenCV, PyTorch, and TensorFlow. At this stage, stored data is ready for computer vision model training. From here, trained models are ready for deployment to make new data predictions.
Conclusion
AI/ML practitioners, data engineers, and computer vision developers have a lot to gain from the efficiency of ReductStore in its effective computer vision data storage, retrieval, and analysis. Leveraging ReductStore’s capabilities effectively addresses challenges related to handling large volumes of computer vision data. Conquering these storage challenges fuels organizations to their full potential leading to inevitable innovation drives in AI and machine learning.
