Realtime scrapper: scrap all pasties,github,reddit..etc in real time
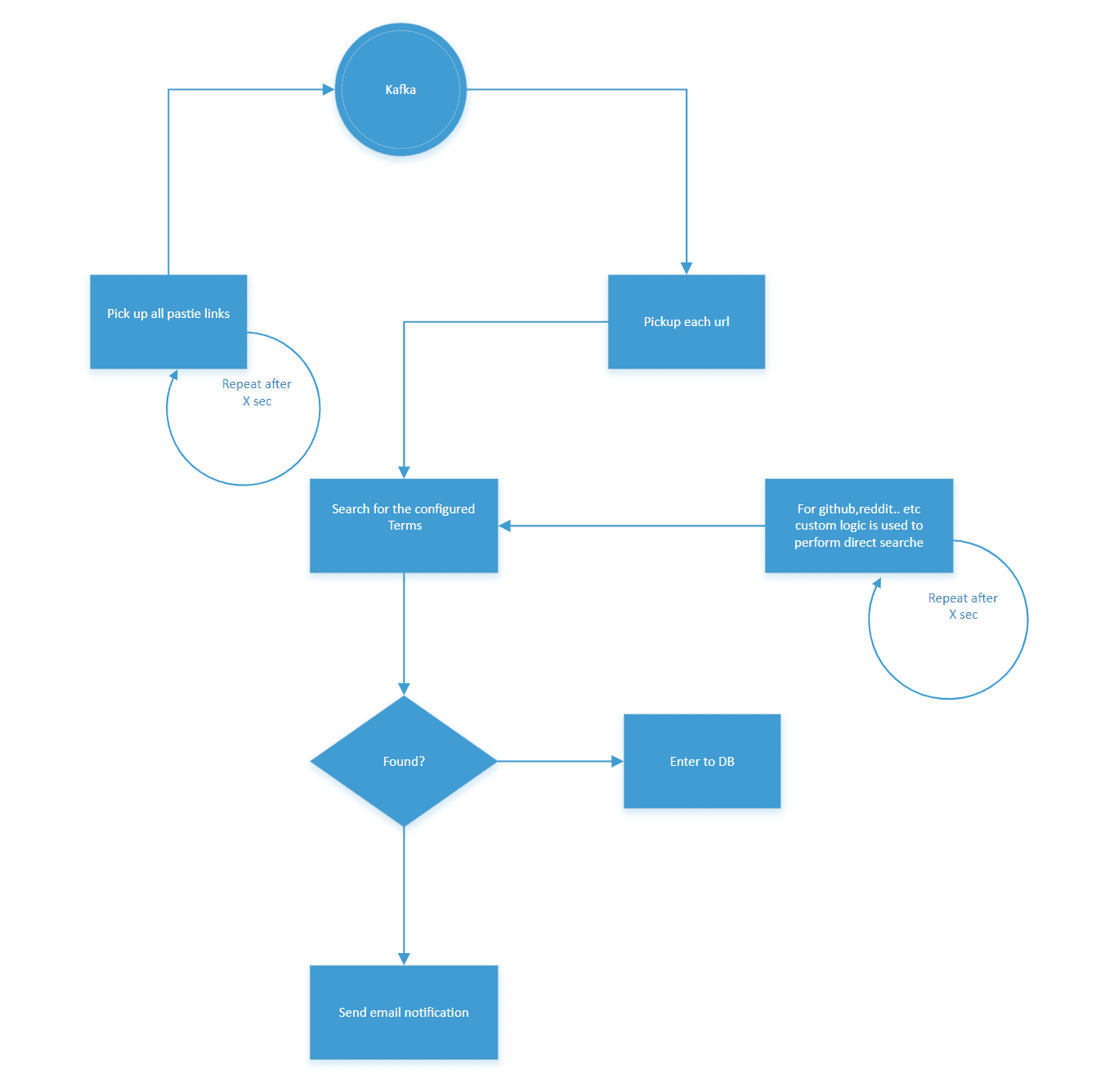
RTS (Realtime scrapper) is a tool developed to scrap all pasties,github,reddit..etc in real time to identify the occurrence of search terms configured. Upon the match, an email will be triggered. Thus allowing the company to react in case of leakage of code, any hacks tweeted..etc.. and harden themselves against an attack before it goes viral.
The same tool in malicious user hands can be used offensively to get the update on any latest hacks, code leakage etc..
List of sites which will be monitored are:
- Non-Pastie Sites
- Github
- Pastie Sites
- Pastebin.com
- Codepad.org
- Dumpz.org
- Snipplr.com
- Paste.org.ru
- Gist.github.com
- Pastebin.ca
- Kpaste.net
- Slexy.org
- Ideone.com
- Pastebin.fr
Architecture
Configuration
Before using this tool is is neccessary to understand the properties file present in scrapper_config directory.
-
-
- consumer.properties: Holds all the neccessary config data needed for consumer (Refer apache Kafka guide for more information). The values present here are default options and does nto require any changes
- producer.properties: Holds all the neccessary config data needed for Producer (Refer apache Kafka guide for more information).The values present here are default options and does nto require any changes
- email.properties: Configure SMTP server with email id’s.
- scanner-configuration.properties: This is the core configuration file. Update all the config for enabling search on twitter/github(To get tokens and key refer respective sites). For pastie sites and Reddit, there is no need for any changes in config.
Note: However in all cases make sure to change “searchterms” to values of our choice to search. If there are multiple search terms then add them separate by comma as shown with example terms in the config file.
-
- Understanding more about scanner-configuration.properties file.
-
-
- For any pastie site configuration is as below:
-
- scrapper.(pastie name).profile=(Pastie profile name)
- scrapper.(pastie name).homeurl=(URL from where pastie ids a extracted)
- scrapper.(pastie name).regex=(Regex to fetch pastie ids)
- scrapper.(pastie name).downloadurl= (URL to get information about each apstie)
- scrapper.(pastie name).searchterms=(Mention terms to be searched seperated by comma)
- scrapper.(pastie name).timetosleep=(Time for which pastie thread will sleep before fetching pastie ids again)
-
-
- For github search configuration is as below:
-
- scrapper.github.profile=Github
- scrapper.github.baseurl=https://api.github.com/search/code?q={searchTerm}&sort=indexed&order=asc
- scrapper.github.access_token=(Get your own github access token)
- scrapper.github.searchterms=(Mention terms to be searched seperated by comma)
- scrapper.github.timetosleep=(Time for which github thred should sleep before searching again)
-
-
- For reditt search configuration is as below:
-
- scrapper.reddit.profile=Reddit
- scrapper.reddit.baseurl=https://www.reddit.com/search.json?q={searchterm}
- scrapper.reddit.searchterms=(Mention terms to be searched seperated by comma)
- scrapper.reddit.timetosleep=(Time for which github thred should sleep before searching again)
-
-
- For Twitter search configuration is as below:
-
- scrapper.twitter.apikey=test
- scrapper.twitter.profile=Twitter
- scrapper.twitter.searchterms=(Mention terms to be searched seperated by comma)
- scrapper.twitter.consumerKey=(Get your own consumer key)
- scrapper.twitter.consumerSecret=(Get your own consumerSecret)
- scrapper.twitter.accessToken=(Get your own accessToken)
- scrapper.twitter.accessTokenSecret=(Get your own accessTokenSecret)
-
-



