slurp: S3 bucket enumerator
slurp
Enumerates S3 buckets manually or via certstream
Features
- Written in Go:
- It’s faster than python
- No dependency hell and version locks (ie python 3 and requirements.txt, etc)
- Better concurrency
- Punycode support for internationalized domains (S3 doesn’t allow internationalized buckets; so this app just notifies and skips (certstream) or exits (manual mode))
- Domain mode so that you can test individual domains.
- New Keywords mode so that you can attempt enumeration based on keywords. Why is this useful? Sometimes organizations have shorthand names that they go by. If you wanted to test that shorthand name you could not do so previously; now you can by using this mode of enumeration.
- New Supports a list of domains now.
- Certstream mode so that you can enumerate s3 buckets in real time.
- Colorized output for visual grep 😉
- Currently generates over 1200 permutations per domain and keyword
- Strong copyleft license
Usage
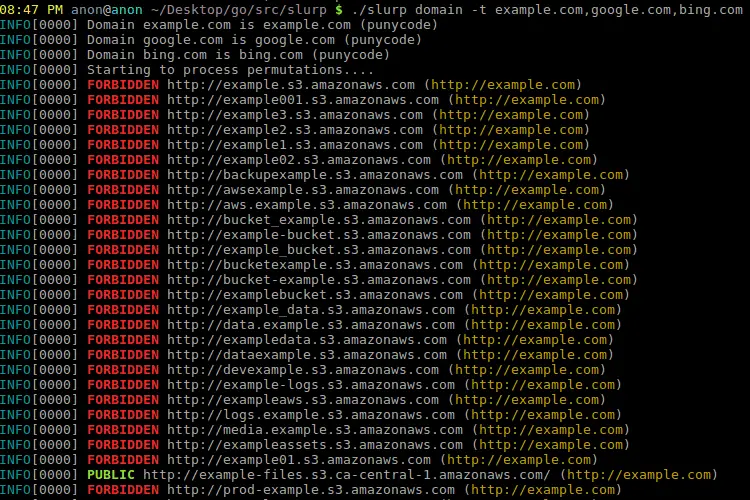
- slurp domain <-t|–target> google.com will enumerate the S3 domains for a specific target.
- slurp keyword <-t|–target> linux,golang,python will enumerate S3 buckets based on those 3 keywords.
- slurp certstream will follow certstream and enumerate S3 buckets from each domain.
- permutations.json stores the permutations that are used by the program; they are in JSON format and loaded during execution this is required; it assumes a specific format per permutation: anything_you_want.%s; the ending .%s is required otherwise the AWS S3 URL will not be attached to it, and therefore no results will come from the S3 enumeration. If you need flexible permutations then you have to edit the source.
Certstream

Domain

Keywords

Source: https://github.com/bbb31/






