spidr: versatile Ruby web spidering library
Spidr
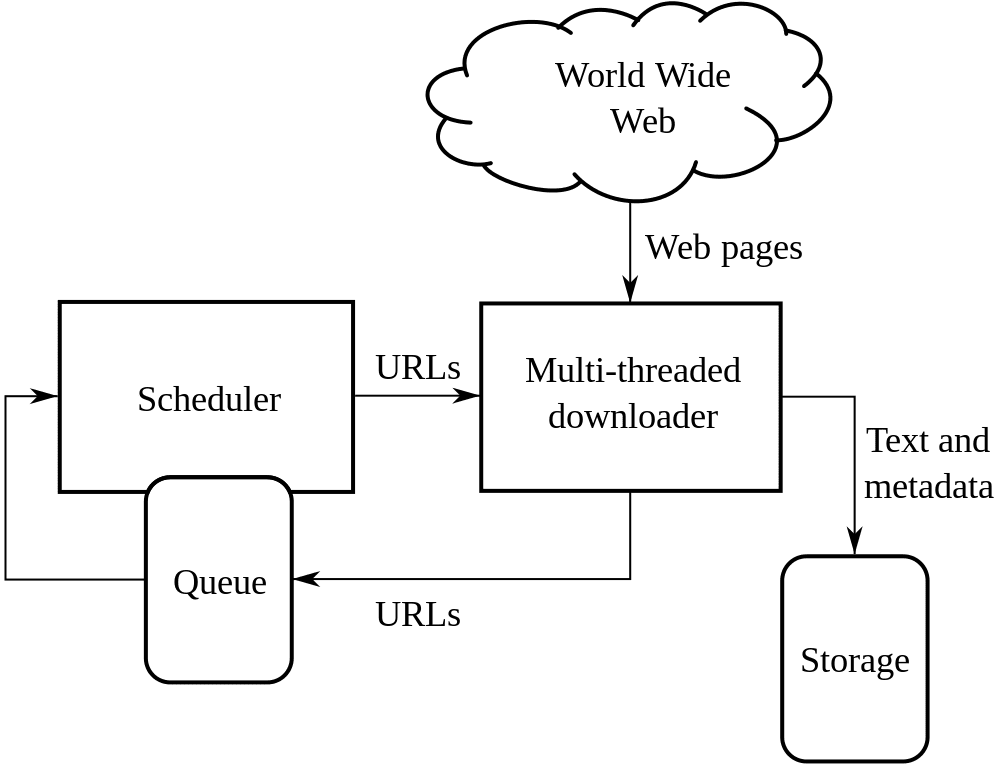
Spidr is a versatile Ruby web spidering library that can spider a site, multiple domains, certain links or infinitely. Spidr is designed to be fast and easy to use.
Features
- Follows:
atags.iframetags.frametags.- Cookie protected links.
- HTTP 300, 301, 302, 303 and 307 Redirects.
- Meta-Refresh Redirects.
- HTTP Basic Auth protected links.
- Black-list or white-list URLs based upon:
- URL scheme.
- Host name
- Port number
- Full link
- URL extension
- Optional
/robots.txtsupport.
- Provides callbacks for:
- Every visited Page.
- Every visited URL.
- Every visited URL that matches a specified pattern.
- Every origin and destination URI of a link.
- Every URL that failed to be visited.
- Provides action methods to:
- Pause spidering.
- Skip processing of pages.
- Skip processing of links.
- Restore the spidering queue and history from a previous session.
- Custom User-Agent strings.
- Custom proxy settings.
- HTTPS support.
Install
$ gem install spidr
Examples
Start spidering from a URL:
Spider as a host:
Spider a site:
Spider multiple hosts:
Do not spider certain links:
Do not spider links on certain ports:
Do not spider links blacklisted in robots.txt:
Copyright (c) 2008-2016 Hal Brodigan
Source: https://github.com/postmodern/





