Photo by Nate Grant on Unsplash
Open source is currently making developers’ lives easier by allowing them to build simple functionalities without having to create and debug the code because. Developers can use the open source components that provide the functionalities they are trying to implement, simplifying the process immensely. Keeping track of all the open source components that make up software can be a difficult and time-consuming operation as your software is always made up of a large number of diverse components.
These days, securing the individual components of a software is an absolute necessity because new vulnerabilities are being discovered in open source code and attacks are being carried out on supply chains with increasing frequency.
Since the source code is accessible to the public and anybody can modify it to suit their needs, open source softwares are immensely popular. However, one must not forget they are also prone to having vulnerabilities. This is why it is important to keep a record of the components you are utilizing or, to put it another way, have an open source inventory of the components that are currently in use.
Should Tracking Open Source Components Be Automated?
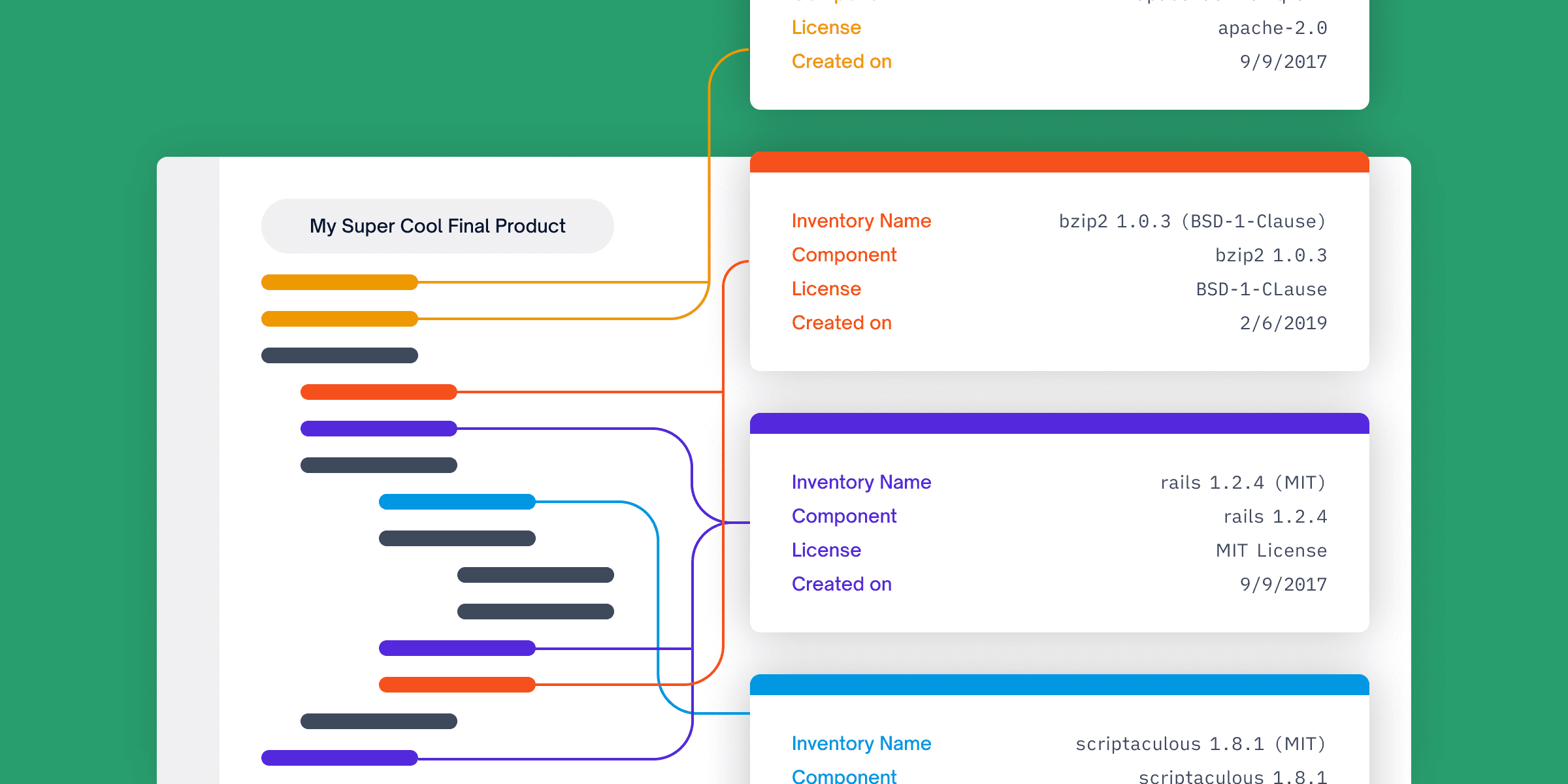
There are various reasons why open source components should be tracked. The inventory, for example, will provide you complete visibility into your open source components, which is necessary for managing these components effectively. There are some open source licenses that are incompatible because they might have varying types of permissions and requirements, which could lead to a conflict. Additionally, these open source components might have vulnerabilities in them which might cause a lot of issues and even make the whole organization vulnerable.
When this tracking is done manually, a developer is responsible for going through all the information (which may include licences, the components it is using within the software along with their version number) and even maintaining a software bill of materials (SBOM). However, doing these manually not only increases the burden on the developer, but also leaves the door open for human error, which can lead to very bad consequences. Manually tracking is hard and a waste of valuable time. That time can instead be invested in the development of a product.
Consequently, a method that is automated should be employed to track all of these components and their licences, among other things. Software composition analysis, also known as SCA, uses automated software that takes care of everything for you. You will have complete control over all of the open source components in your system. It is possible to integrate it with any build tool, run it in the background as part of your CI/CD environment, and use it to determine the open source components and dependencies that are already in use.
It gathers all of the components, generates the SBOM, and then compares it to the information in the NVD database to locate any vulnerabilities that may exist in that particular version. Additionally, it will inform you of any licence issues. Because you are carrying out each and every process in an automated manner, your team is free to concentrate their attention entirely on development, and the automated tools can easily keep track of each and every component for you.
Conclusion
When we do things manually, keeping track of open source components can be a difficult and time-consuming effort. If things aren’t done properly, even the smallest of mistakes has the potential to make things much worse and put the security of the entire business at risk. As a result, an automated method ought to be taken into consideration because it will address a lot of issues and minimize the attack surface of the company.
Hence, organizations should take SCA into consideration. It will help you do things like maintain a list of components and track licensing in a more effective manner on a daily basis, and improve the security of your software and organization in a larger sense.