FLUFFI: A distributed evolutionary binary fuzzer for pentesters
FLUFFI
FLUFFI (Fully Localized Utility For Fuzzing Instantaneously) is a distributed feedback-based evolutionary fuzzer developed by Siemens STT (formerly CSA) designed specifically for the SIEMENS environment.
“Designed specifically for the SIEMENS environment” means that the fuzzer is optimized for those challenges that we usually face during our penetration tests / Red-Team activities for Siemens:
- Usually binary only
- Diversity of test targets: Windows/Linux, embedded/desktop, user-mode / kernel, different interfaces(file, network, API, …)
- Limited time for harnessing in typical security assessments
- Fuzzing environment (hardware) needs to be available
Feedback-based evolutionary fuzzer in short means that FLUFFI does not require knowledge about what it fuzzes. It does not need to know that “The target’s input is HTML, and HTML is specified as follows: …”.
Instead, FLUFFI monitors the behavior of the target program when confronted with certain input. Currently, this means collecting all basic blocks the program used while processing an input (might be extended in the future). FLUFFI starts each FuzzJob with an initial population of known-to-be-valid inputs. Based on this set, FLUFFI creates input mutations, feeds them to the target, and collects the covered basic block. Each mutation that created new coverage (i.e. new basic blocks) is subsequently added to the population.
Other popular feedback-based evolutionary fuzzers are AFL, WinAFL, and honggfuzz.
Pros:
- Can fuzz arbitrary (unknown) protocols and formats
- The evolutionary algorithm might be an interesting research area
- Testcase generation flexible (e.g. Concolic execution)
Cons:
- Needs a feedback loop (e.g. debugger, tracer)
Further core design decisions:
Do not try to maximize test cases/sec. Instead, try to generate inputs that are as good as possible.
As fuzzing binaries is slow, and fuzzing embedded system binaries is even slower, FLUFFI’s principle design decisions are:
Pros:
- We can effectively fuzz slow binaries
- We can effectively fuzz embedded systems
- We can research fancy techniques such as concolic execution for testcase generation
Cons:
- Much fewer test cases/sec than e.g. AFL
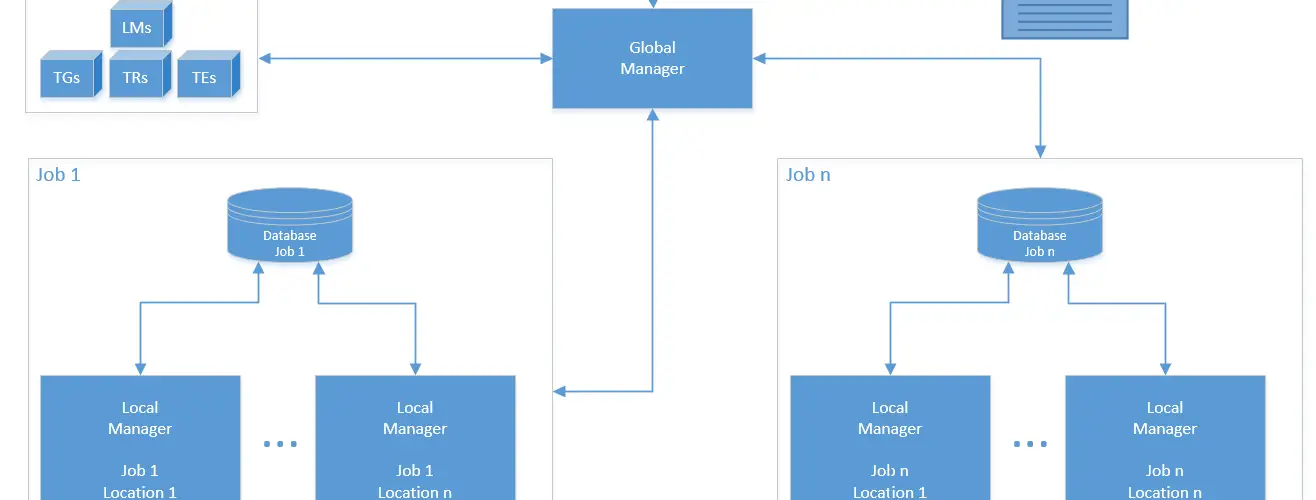
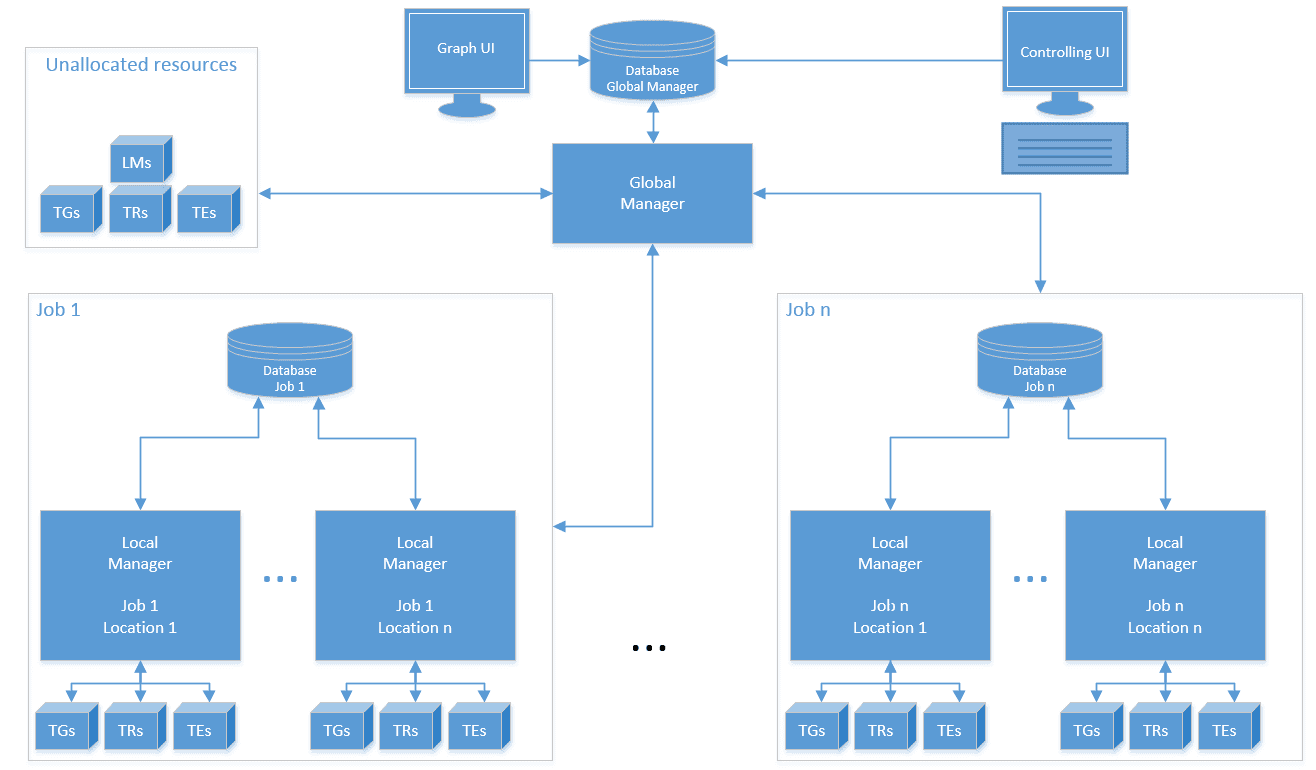
Make FLUFFI a modular system that communicates over the network
Pros:
- Test cases are not generated on the same system that runs them. A crash in a (kernel) runner does not lead to a loss of a crashing test case
- Binary fuzzing tends to mess up runner systems badly. Those should be restarted/reinitialized frequently while a fuzz job is running
- Costly testcase generation can be done on dedicated systems that do not run test cases
- Embedded systems can be connected to the systems. They only need to run the runner and not the generator, etc…
- We can fuzz targets that require exclusive resources (such as “port 80” or “named pipe XYZ”) in parallel without modifying them. This supports our vision of “minimal harnessing”
- Nicely scalable: Just plug in more components in a network
- Easy replacement and benchmarking of components (e.g. for research)
- Network communication would allow combining cloud systems (cheap, easily scalable) with real systems (e.g. native ARM systems, hardware tracing, special hardware)
Cons:
- IO is high. An all-in-one process would be much faster. However, due to the first design decision of prioritizing quality over quantity, this is fine.
FLUFFI agents are stateless – Persistent Info is stored in DB to which only LM and GM connect
Pros:
- Agents may crash or disconnect – the system keeps working
- Runner systems can be power-cycled / reinstalled without losing data
- Agents can easily be added to the system for scalability
- DB bottlenecks can be solved with classical DB scaling (e.g., cluster)
- Info can easily be accessed and be visualized in a web application or used for sophisticated analysis
Cons:
- DB as data storage is very slow in comparison to in-memory storage
Install && Use
Copyright 2017-2020 Siemens AG