fuzztruction: an academic prototype of a fuzzer
Fuzztruction
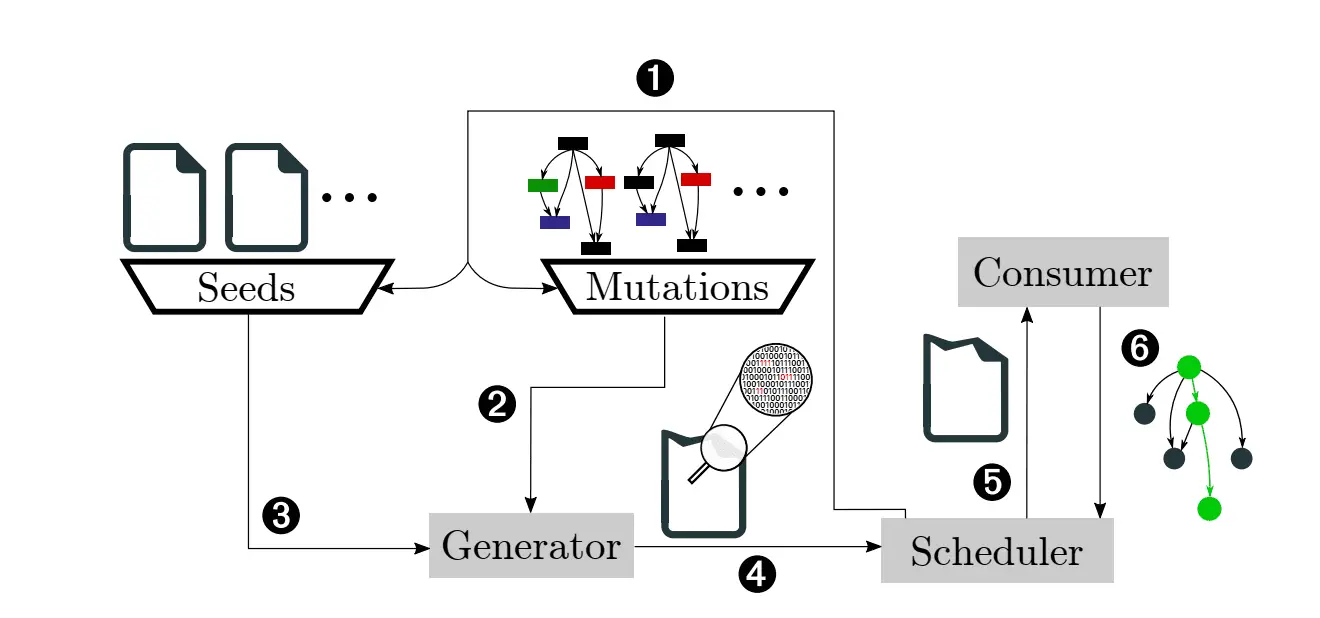
Fuzztruction is an academic prototype of a fuzzer that does not directly mutate inputs (as most fuzzers do) but instead uses a so-called generator application to produce an input for our fuzzing target. As programs generating data usually produce the correct representation, our fuzzer mutates the generator program (by injecting faults), such that the data produced is almost valid. Optimally, the produced data passes the parsing stages in our fuzzing target, called consumer, but triggers unexpected behavior in deeper program logic. This allows to even fuzz targets that utilize cryptography primitives such as encryption or message integrity codes. The main advantage of our approach is that it generates complex data without requiring heavyweight program analysis techniques, grammar approximations, or human intervention.
For instructions on how to reproduce the experiments from the paper, please read the fuzztruction-experiments submodule documentation after reading this document.
Components
Fuzztruction contains the following core components:
Scheduler
The scheduler orchestrates the interaction of the generator and the consumer. It governs the fuzzing campaign, and its main task is to organize the fuzzing loop. In addition, it also maintains a queue containing queue entries. Each entry consists of the seed input passed to the generator (if any) and all mutations applied to the generator. Each such queue entry represents a single test case. In traditional fuzzing, such a test case would be represented as a single file. The implementation of the scheduler is located in the scheduler directory.
Generator
The generator can be considered a seed generator for producing inputs tailored to the fuzzing target, the consumer. While common fuzzing approaches mutate inputs on the fly through bit-level mutations, we mutate inputs indirectly by injecting faults into the generator program. More precisely, we identify and mutate data operations the generator uses to produce its output. To facilitate our approach, we require a program that generates outputs that match the input format the fuzzing target expects.
The implementation of the generator can be found in the generator directory. It consists of two components that are explained in the following.
Compiler Pass
The compiler pass (generator/pass) instruments the target using so-called patch points. Since the current (tested on LLVM12 and below) implementation of this feature is unstable, we patch LLVM to enable them for our approach. The patches can be found in the llvm repository (included here as a submodule). Please note that the patches are experimental and not intended for use in production.
The locations of the patch points are recorded in a separate section inside the compiled binary. The code related to parsing this section can be found at lib/llvm-stackmap-rs, which we also published on crates.io.
During fuzzing, the scheduler chooses a target from the set of patch points and passes its decision down to the agent (described below) responsible for applying the desired mutation for the given patch point.
Agent
The agent, implemented in generator/agent is running in the context of the generator application that was compiled with the custom compiler pass. Its main tasks are the implementation of a forkserver and communicating with the scheduler. Based on the instruction passed from the scheduler via shared memory and a message queue, the agent uses a JIT engine to mutate the generator.
Consumer
The generator’s counterpart is the consumer: It is the target we are fuzzing that consumes the inputs generated by the generator. For Fuzztruction, it is sufficient to compile the consumer application with AFL++’s compiler pass, which we use to record the coverage feedback. This feedback guides our mutations of the generator.