Andy0101 [Public domain], <a href="https://commons.wikimedia.org/wiki/File:TTS_System.svg">via Wikimedia Commons</a>
Speech synthesis processes an artificial voice that generates from a machine that reads out texts making it easier for visually impaired people and/or dyslexic people. The technology is known as Text-To-Speech (TTS). It has now become so common these days and is available in almost all smartphones.
Speech synthesis has a number of benefits in all kinds of fields. Those of you who didn’t know the meaning of TTS or speech synthesizer earlier would probably know what it is now by reading the article.
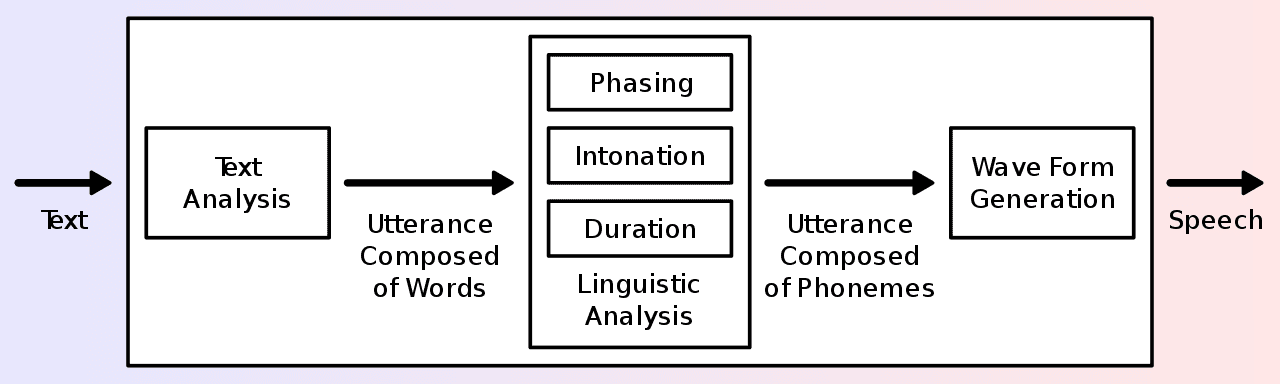
How speech synthesis works involve three essential stages; text to words, words to phonemes, and phonemes to sound.
- Text to words
It is easy for an adult to read a short or a long paragraph but when you ask the same paragraph to be read by a child, it gets challenging. The main reason is that the written text is ambiguous; a single word may have a different meaning and you may require proper knowledge or help from an educated person to make you understand under what context the word is used for. So, to reduce the ambiguity by narrowing down the article in a proper and easy manner to read and understand is the first step which is referred to as pre-processing or normalization.
English is a difficult language with lots of grammar and vocabulary rules. It is easy for a human being to know how to read numbers, dates, times, units, symbols, acronyms, synonyms and homonyms. But the same work is difficult for a machine to do. For example, the word ‘read’ can be pronounced in two ways- ‘read’ and ‘reed’. How would the computer know which one to pronounce? So they use statistical probability techniques or neural networks to arrive at the most likely pronunciation by comparing with the tense of the sentence.
- Words to phonemes
Once the computer understands and converts the text to voice, the speech synthesizer has to generate the speech sounds. As we’ve already mentioned above, it is a pretty difficult task for a computer to read out the same words with a different pronunciation. The best alternative solution is to break the written words into graphemes. Once that’s done, the computer should be able to generate phonemes that correspond to them. This process will require a set of simple rules for the computer to follow. This is similar to a child reading words he or she has never encountered in their lives. For a person, a single line can be spoken with different styles and emotions while it is very difficult for a machine to do. The advantage of doing this is that the computer at least tries its best at reading any word.
- Phonemes to sound
This is the final step of how speech synthesis works. The conversion of phonemes to sound is possible in 3 different ways:
- The first way is to use recordings of humans saying the phonemes
- Another way is for the computer to generate the phonemes itself by generating basic sound frequencies. The most relevant example could be a music synthesizer.
- The last way is to mimic the mechanism of the human voice.
