nautilus: A grammar based feedback Fuzzer
Nautilus 2.0
Nautilus is a coverage guided, grammar-based fuzzer. You can use it to improve your test coverage and find more bugs. By specifying the grammar of semi-valid inputs, Nautilus is able to perform complex mutation and to uncover more interesting test cases. Many of the ideas behind this fuzzer are documented in a Paper published at NDSS 2019.
Version 2.0 has added many improvements to this early prototype and is now 100% compatible with AFL++. Besides general usability improvements, Version 2.0 includes lots of shiny new features:
- Support for AFL-Qemu mode
- Support for grammars specified in python
- Support for non-context free grammars using python scripts to generate inputs from the structure
- Support for specifying binary protocols/formats
- Support for specifying regex-based terminals that aren’t part of the directed mutations
- Better ability to avoid generating the same very short inputs over and over
- Massive cleanup of the codebase
- Helpful error output on invalid grammars
- Fixed a bug in the timeout code that occasionally deadlocked the fuzzer
How Does Nautilus Work?
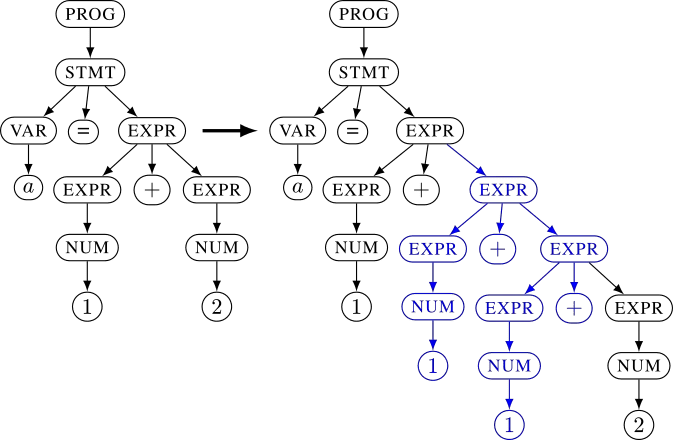
You specify a grammar using rules such as EXPR -> EXPR + EXPR or EXPR -> NUM and NUM -> 1. From these rules, the fuzzer constructs a tree. This internal representation allows to apply much more complex mutations than raw bytes. This tree is then turned into a real input for the target application. In normal Context-Free Grammars, this process is straightforward: all leaves are concatenated. The left tree in the example below would unparse to the input a=1+2 and the right one to a=1+1+1+2. To increase the expressiveness of your grammars, using Nautilus you are able to provide python functions for the unparsing process to allow much more complex specifications.
Download && Use
Copyright (C) 2020 nautilus-fuzz



