SourceWolf
Amazingly fast response crawler to find juicy stuff in the source code!
What can SourceWolf do?
- Crawl through responses to find hidden endpoints, either by sending requests or from the local response files (if any).
- Brute forcing host using a wordlist.
- Get the status codes for a list of URLs / Filtering out the live domains from a list of hosts.
All the features mentioned above execute with great speed.
- SourceWolf uses the Session module from the requests library, which means, it reuses the TCP connection, making it really fast.
- SourceWolf provides you with an option to crawl the responses files locally so that you aren’t sending requests again to an endpoint, whose response you already have a copy of.
- The final endpoints are in a complete form with a host like https://example.com/api/admin are not as /api/admin. This can come useful when you are scanning a list of hosts.
Changelog v1.8
- new-features:
SourceWolf can now grab github and linkedin profiles along with social media links!
Use
-
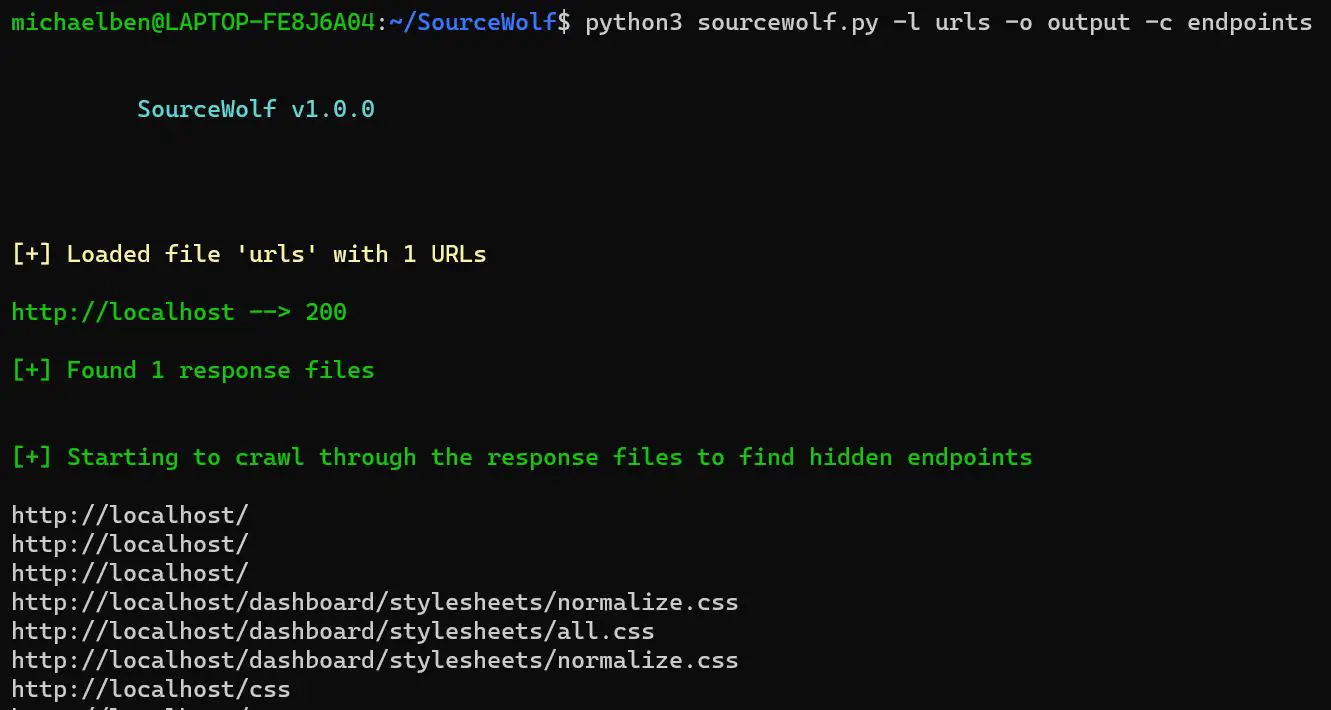
Crawl response mode:
Complete usage:
python3 sourcewolf.py -l domains -o output/ -c crawl_output
domains is the list of URLs, which you want to crawl in the format:
https://example.com/ https://exisiting.example.com/ https://exisiting.example.com/dashboard https://example.com/hitme
output/ is the directory where the response text files of the input file are stored.
They are stored in the format output/2XX, output/3XX, output/4XX, and output/5XX.
output/2XX stores 2XX status code responses, and so on!
crawl_output specified using the -c flag is used to store the output, inside a directory which SourceWolf produces by crawling the HTTP response files, stored inside the output/ directory (currently only endpoints)
crawl_output/ directory will contain an endpoint file, which contains all the endpoints collected by SourceWolf. The directory will have more files, as more modules, and features are integrated into SourceWolf.
-
Brute force mode
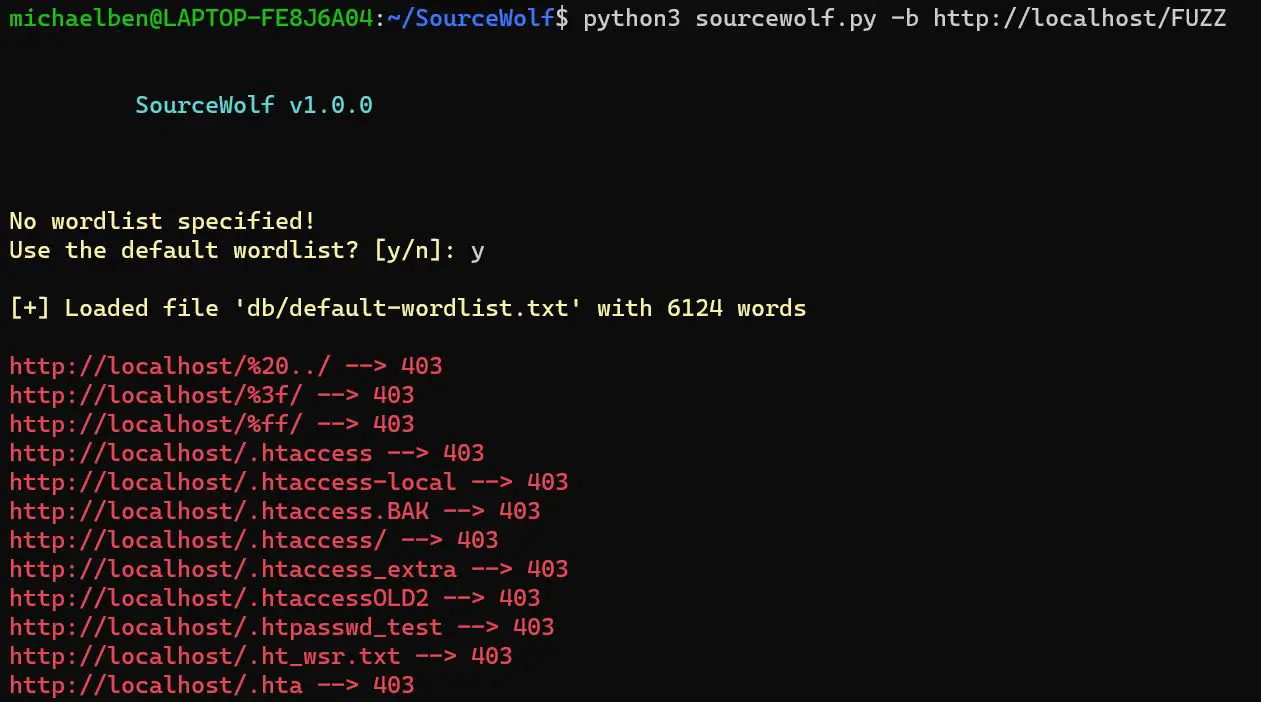
python3 sourcewolf.py -b https://hackerone.com/FUZZ -w /path/to/wordlist -s status
-w flag is optional. If not specified, it will use a default wordlist with 6124 words
SourceWolf replaces the FUZZ keyword from the -b value with the words from a wordlist, and sends the requests. This enables you to brute force get parameter values as well.
-s will store the output in a file called status
-
Probing mode
Screenshot not included as the output looks similar to crawl response mode.
python3 sourcewolf -l domains -s live
The domains file can have anything like subdomains, endpoints, js files.
The -s flag write the response to the live file.
Both the brute force and probing mode prints all the status codes except 404 by default. You can customize this behavior to print only 2XX responses by using the flag –only-success
SourceWolf also makes use of multithreading.
The default number of threads for all modes is 5. You can increase the number of threads using the -t flag.
In addition to the above three modes, there is an option crawl locally, provided you have them locally, and follow sourcewolf compatible naming conventions.
Store all the responses in a directory, say responses/
python3 sourcewolf.py --local responses/
This will crawl the local directory, and give you the results.
Copyright (c) 2020 Harinarayanan K S
Source: https://github.com/micha3lb3n/
