stoq v3.0.1 releases: open source framework for enterprise level automated analysis
stoQ is an automation framework that helps to simplify the more mundane and repetitive tasks an analyst is required to do. It allows analysts and DevSecOps team the ability to quickly transition from different data sources, databases, decoders/encoders, and numerous other tasks. It was designed to be enterprise-ready and scalable, while also being lean enough for individual security researchers.
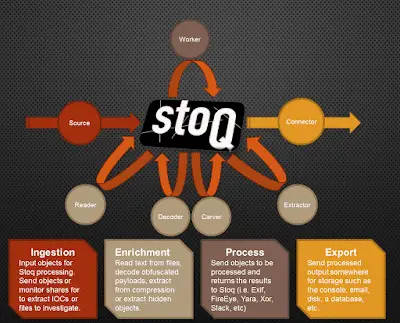
Fundamentally, stoQ is structured to be in the middle of your analyst workflow. It works best when it can leverage other security tools to ingest objects and a database to store the output. Let’s take a look at how stoQ is structured.
Ingestion
For sources, stoQ can ingest data from individual files, monitor a directory for new files, pull from a database, or from an API. This is where stoQ at scale can be extremely powerful. Extracting files from threat vectors like HTTP or e-mail can be sent to stoQ for automatic enrichment and processing. This is when file extraction from Suricata or Bro can be used to ingest files for stoQ processing. Sending all executables, PDFs, or Office Documents would allow us to automatically analyze our higher risk file types as they hit our network.
Enrichment
Reader, Decoder, Extractor and Carver plugins that can be used to run the gamut of common activities against ingested files. Use reader plugins to extract text and look for keywords. Use decoder plugins to automatically handle XOR-encoded content or decode base64 strings. Extractors can automate the tasks like decompressing archives and deflating streams in PDF documents. Carver plugins are used to extract hidden payloads, like shellcode or flash files embedded within Word Documents. These enriched objects are then passed back to the stoQ framework for additional processing.
Processing
The Worker class plugins are what interact with external systems to allow objects to be processed elsewhere and return the information back to stoQ to be associated with the object. This allows stoQ to interact with scripts (exiftool, TRiD, Yara, etc.) and APIs (FireEye, VirusTotal, ThreatCrowd, etc.) and get even more data about our objects. Remember, we are able to automate all of this and can quickly scale to requirements.
Export
Once stoQ has ingested, enriched, and processed an object, the results are sent to a Connector plugin for storage. This can be as simple as a regular text file or a database, or as complex as multiple databases spread across multiple data centres.
Leveraging that data with something like ElasticSearch or Splunk can give us a very rich resource of metadata for the objects that have passed through stoQ. This large and detailed dataset can be used to find larger trends and anomalies in your environment. stoQ enables you to craft queries and alerts for all of this metadata.
Changelog v3.0.1
Added
- Add
getjson()function to allow plugins to use valid json strings are configuration
options (@ytreister, #144)
Changed
- Fix stoq command line to properly parsed
--plugin-optsand--request-source
arguments that contain=or:characters - Ensure
always_dispatchinstoq.cfgleveragesgetlist()whenStoq()is
is instantiated. (#149) - Multiple fixes and updates to Dockerfile
Download && Use
Copyright 2014-2017 PUNCH Cyber Analytics Group