subcrawl: find, scan and analyze open directories
SubCrawl
SubCrawl is a framework developed by Patrick Schläpfer, Josh Stroschein, and Alex Holland of HP Inc’s Threat Research team. SubCrawl is designed to find, scan and analyze open directories. The framework is modular, consisting of four components: input modules, processing modules, output modules, and the core crawling engine. URLs are the primary input values, which the framework parses and adds to a queuing system before crawling them. The parsing of the URLs is an important first step, as this takes a submitted URL and generates additional URLs to be crawled by removing sub-directories, one at a time until none remain. This process ensures a more complete scan attempt of a web server and can lead to the discovery of additional content. Notably, SubCrawl does not use a brute-force method for discovering URLs. All the content scanned comes from the input URLs, the process of parsing the URL, and discovery during crawling. When an open directory is discovered, the crawling engine extracts links from the directory for evaluation. The crawling engine determines if the link is another directory or if it is a file. Directories are added to the crawling queue, while files undergo additional analysis by the processing modules. Results are generated and stored for each scanned URL, such as the SHA256 and fuzzy hashes of the content if an open directory was found, or matches against YARA rules. Finally, the result data is processed according to one or more output modules, of which there are currently three. The first provides integration with MISP, the second simply prints the data to the console, and the third stores the data in an SQLite database. Since the framework is modular, it is not only easy to configure which input, processing, and output modules are desired, but also straightforward to develop new modules.
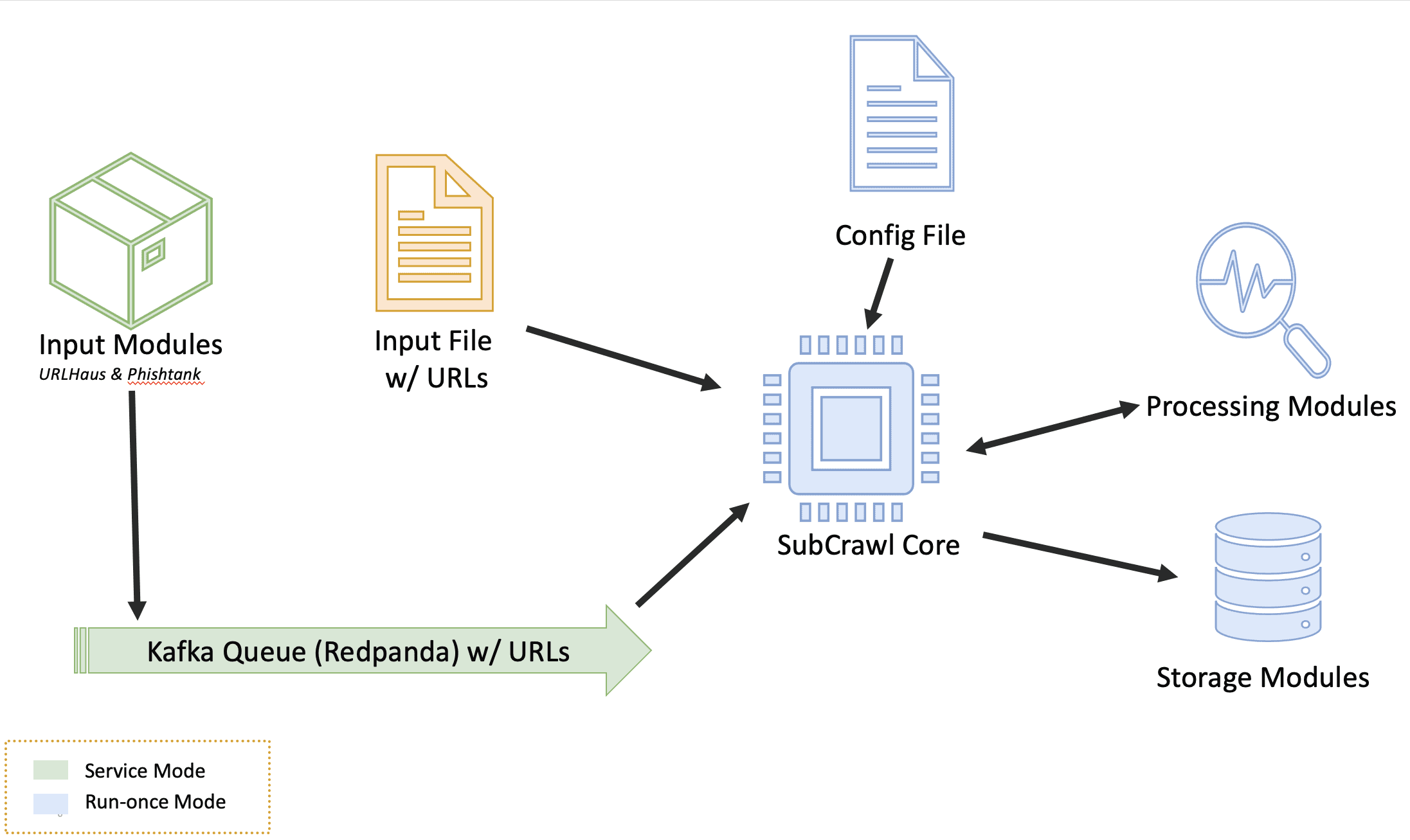
SubCrawl supports two different modes of operation. First, SubCrawl can be started in a run-once mode. In this mode, the user supplies the URLs to be scanned in a file where each input value is separated by a line break. The second mode of operation is service mode. In this mode, SubCrawl runs in the background and relies on the input modules to supply the URLs to be scanned. Figure 1 shows an overview of SubCrawl’s architecture. The components that are used in both modes of operation are blue, run-once mode components are yellow, and service mode components are green.
Install & Use
© Copyright 2021 HP Development Company, L.P.






