turbinia: Automation and Scaling of Digital Forensics Tools

Turbinia is an open-source framework for deploying, managing and running forensic workloads on cloud platforms. It is intended to automate running of common forensic processing tools (i.e. Plaso, TSK, strings, etc) to help with processing evidence in the Cloud, scaling the processing of large amounts of evidence, and decreasing response time by parallelizing processing where possible.
How it works
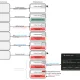
Turbinia is composed of different components for the client, server, and the workers. These components can be run on local physical machines or in the Cloud. The Turbinia client makes requests to process evidence to the Turbinia server. The Turbinia server creates logical jobs from these incoming user requests, which creates and schedules forensic processing tasks to be run by the workers. The evidence to be processed will be split up by the jobs when possible, and many tasks can be created in order to process the evidence in parallel. One or more workers run continuously to process tasks from the server. Any new evidence created or discovered by the tasks will be fed back into Turbinia for further processing.
Communication from the client to the server is currently done transparently with Google Cloud PubSub. The worker implementation uses PSQ (a Google Cloud PubSub Task Queue) for task scheduling.
Install
Usage
The basic steps to get things running after the initial installation and configuration are:
- Start Turbinia server component with
turbiniactl servercommand - Start one or more Turbinia workers with
turbiniactl psqworker - Send evidence to be processed from the turbinia client with
turbiniactl ${evidencetype} - Check status of running tasks with
turbiniactl status
turbiniactl can be used to start the different components, and here is the basic usage:
The commands for processing the evidence types of rawdisk and directory specify information about evidence that Turbinia should process. By default, when adding new evidence to be processed, turbiniactl will act as a client and send a request to the configured Turbinia server, otherwise if --server is specified, it will start up its own Turbinia server process. Here’s the turbiniactl usage for adding a raw disk type of evidence to be processed by Turbinia:
Copyright 2016 aarontp
Source: https://github.com/google/