wordsmith: creating tailored wordlists
by do son ·
wordsmith.rb
The aim of Wordsmith is to assist with creating tailored wordlists and usernames that are primarily based on geolocation.
Authors: @kawabungah & @porterhau5.
Wild West Hackin’ Fest 2017 presentation.
Wordsmith Parsers project: https://github.com/skahwah/wordsmith_parsers.
Installation
Start by cloning the repo or downloading the latest release:
$ git clone https://github.com/skahwah/wordsmith.git
Cloning into 'wordsmith'...
remote: Counting objects: 165, done.
remote: Compressing objects: 100% (62/62), done.
remote: Total 165 (delta 55), reused 117 (delta 55), pack-reused 48
Receiving objects: 100% (165/165), 61.99 KiB | 1.05 MiB/s, done.
Resolving deltas: 100% (92/92), done.
Then download the latest data.tar.xz from the Releases page and place it into the wordsmith directory:
$ cd wordsmith
$ ruby wordsmith.rb
wordsmith v2.1.1
Written by: Sanjiv Kawa (@kawabungah) & Tom Porter (@porterhau5)
[!] data/regions.csv and data.tar.xz not detected! Try downloading data.tar.xz:
$ wget https://github.com/skahwah/wordsmith/releases/download/v2.1.1/data.tar.xz
[!] If data.tar.xz is downloaded, then try changing to the wordsmith directory.
$ wget https://github.com/skahwah/wordsmith/releases/download/v2.1.1/data.tar.xz
On next run, Wordsmith will unpack some files from data.tar.xz to complete the installation. This may take a few seconds:
$ ruby wordsmith.rb
wordsmith v2.1.1
Written by: Sanjiv Kawa (@kawabungah) & Tom Porter (@porterhau5)
[*] Hello new wordsmither!
[*] This script will remove the data/ directory in the current working directory. Enter 'y' to continue: y
[*] Just need to unpack some files (Running: tar -xf data.tar.xz)
[*] Unpack completed!
[*] CeWL found: /usr/bin/cewl
Usage
$ ruby wordsmith.rb
wordsmith v2.1.1
Written by: Sanjiv Kawa (@kawabungah) & Tom Porter (@porterhau5)
Usage: ruby wordsmith.rb [options]
Main Arguments:
-I, --input <input> Comma-delimited list of inputs, see -E for examples and detailed usage
Input Options:
-a, --all Grab all options
-b, --other Grab other miscellaneous attributes
-e, --cia Grab demographics compiled by the CIA
-c, --cities Grab all city names
-f, --colleges Grab all college sports
-l, --landmarks Grab all landmarks
-v, --language Grab the most popular language(s)
-N, --all-names Grab all first names and last names
-G, --first-names Grab all first names
-L, --last-names Grab all last names
-p, --phone Grab all area codes
-r, --roads Grab all road names
-g, --religion Grab the most popular religious text(s)
-t, --teams Grab all major sports teams
-u, --counties Grab all counties
-z, --zip Grab all zip codes
--lands Grab all land features
--places Grab all populated places
--structures Grab all structures/buildings
--waters Grab all water/island features
Username Generation Options:
--filn FirstInitialLastName (bsmith)
--fnln FirstNameLastName (bobsmith)
--fnli FirstNameLastInitial (bobs)
--lnfi LastNameFirstInitial (smithb)
--lnfn LastNameFirstName (smithbob)
--fidln FirstInitial.LastName (b.smith)
--fndln FirstName.LastName (bob.smith)
--truncate LEN Truncate username at LEN number of characters (bobsmi)
--max-users LEN Max number of usernames to generate
--name-depth LEN Num of first/last names to iterate over (default:100, 0 will get all)
Web Scrape Options:
-d, --domain DOMAIN Set a URL for a web application that you want CeWL to scrape
-i, --infile FILE Supply a file containing multiple URLs that you want CeWL to scrape
Output Options:
-o, --output FILE The filename for writing output
-q, --quiet Don't show words generated, use with -o option
-k, --min-length LEN Minimum length of word to include
-n, --max-length LEN Maximum length of word to include
-D, --complexity Words must meet Windows default complexity (8 char min, 3/4 cases)
-j, --lowercase Convert all words to lowercase
-w, --specials Add words with special characters removed
-x, --spaces Add words with spaces removed
-y, --split Split words by space and add
-m, --mangle Add all permutations (-w, -x, -y)
-P, --prepend-phones Prepend state area codes to each generated word
-A, --append-phones Append state area codes to each generated word
-X, --prepend-zips Prepend zip codes to each generated word
-Z, --append-zips Append zip codes to each generated word
-W, --prepend-wordlist FILE Prepend words in FILE to each generated word
-Y, --append-wordlist FILE Append words in FILE to each generated word
Info Options:
-C, --show-child-nodes Show all possible child nodes for each input
-E, --examples Show some usage examples and detailed explanations about using wordsmith
-R, --show-regions Show regions mapping
Command Examples
$ ruby wordsmith.rb -E
wordsmith v2.1.1
Written by: Sanjiv Kawa (@kawabungah) & Tom Porter (@porterhau5)
Input names:
------------
Valid inputs for wordsmith (using -I option) are based on nodes located in the "data" directory.
The top-level nodes are countries labeled by their 3-letter ISO Country Code:
data/gbr : Great Britain
data/usa : United States
data/deu : Germany
etc.
Some countries are divided into states, provinces, counties, or municipalities. These child nodes
are nested beneath the parent:
data/can/on : Ontario, Canada
data/usa/nc/raleigh : Raleigh, NC, USA
data/gbr/eng/sx/east_sussex : East Sussex, Sussex, England, Great Britain
Inputs for wordsmith use these node paths, but with a hyphen (-) delimiter:
ruby wordsmith.rb -I gbr [options]
ruby wordsmith.rb -I can-on [options]
ruby wordsmith.rb -I usa-nc-raleigh [options]
If you prefer to not dig through the "data" directory looking for potential inputs or attributes,
use -C to show children nodes for a given input:
ruby wordsmith.rb -I all -C (show all potential nodes)
ruby wordsmith.rb -I usa -C (show children nodes of USA)
ruby wordsmith.rb -I gbr-eng -C (show children nodes of England)
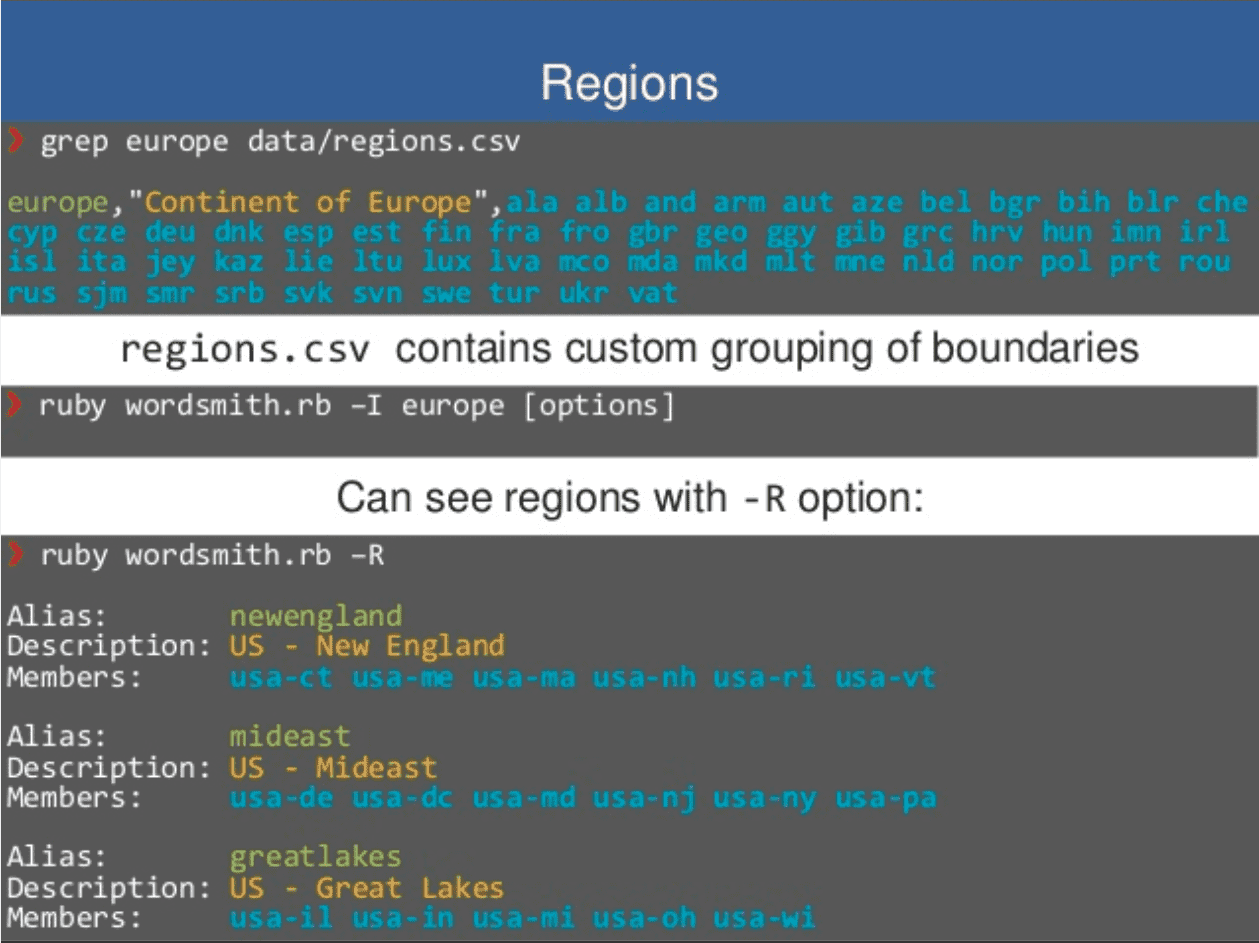
Alternatively, inputs can also be user-defined through the use of the "regions.csv" file. Wordsmith
ships with a few regions already defined, such as:
Continents : africa, asia, europe, etc.
US regions : southeast, newengland, greatlakes, etc.
Unions/Assoc. : eu, asean, nafta, etc.
These region aliases can be found by inspecting "regions.csv" or by using the -R option:
ruby wordsmith.rb -R
Attributes:
-----------
Each node may have one or more attributes, such as cities, roads, colleges, etc. Wordsmith will recurse
every child node and grab data for the specified attribute. For example, the following syntax starts at
the top-level "usa" node and recurses into every sub-directory looking for zip codes:
ruby wordsmith.rb -I usa -z
Some attributes are widely-used, such as roads (-r), cities (-c), and a handful of others. Use the -h
option to see a listing of those attributes. Some attributes may be unique to an area and don't have a
dedicated option. These can still be grabbed by using the -b option. The -b option will look for all
txt files that are not one of attributes with a dedicated option. For example, if someone generated data
for all of the lakes in Minnesota and placed it in "data/usa/mn/lakes.txt", this can be grabbed using:
ruby wordsmith.rb -I usa-mn -b
Extending wordsmith to incorporate new data is as simple as creating a ".txt" file in the proper data
directory. If you have data that you'd think would benefit other users, please connect with us on GitHub.
Basic usage:
------------
Show all children nodes and attributes for Great Britain
ruby wordsmith.rb -I gbr -C
Grab all of the most popular names for USA
ruby wordsmith.rb -I usa -N
Grab all of the zip codes for California
ruby wordsmith.rb -I usa-ca -z
Grab all of the sports teams for Charlotte, NC, USA
ruby wordsmith.rb -I usa-nc-charlotte -t -m
Grab all of the landmarks for California, Montana, and Florida
ruby wordsmith.rb -I usa-ca,usa-mt,usa-fl -l
Using regions:
--------------
Show regions defined in regions.csv
ruby wordsmith.rb -R
Grab all of the cities for the European Union
ruby wordsmith.rb -I eu -c
Grab all of the roads for New England (U.S.)
ruby wordsmith.rb -I newengland -r
Username generation:
--------------------
Generate usernames with format FirstinitialLastName:
ruby wordsmith.rb -I usa --filn
Generate usernames with format LastnameFirstname, truncate usernames to 8 characters:
ruby wordsmith.rb -I usa --lnfn --truncate 8
Generate usernames with format Firstname.LastName using the 250 most popular first and last names
ruby wordsmith.rb -I usa --fndln --name-depth 250
Output formatting:
------------------
Grab all colleges for California, mangle the output, convert to lowercase
ruby wordsmith.rb -I usa-ca -f -m -j
Grab all roads for England with a minimum character length of 8
ruby wordsmith.rb -I gbr-eng -r -k 8
Grab everything for Italy, write to file named italy.txt
ruby wordsmith.rb -I ita -a -o italy.txt
Create a mega wordlist containing all countries with all options, quiet output, write to file named all.txt
ruby wordsmith.rb -I all -m -q -o all.txt
Web scraping:
-------------
Run CeWL against https://www.popped.io, mangle the output
ruby wordsmith.rb -d https://www.popped.io -m
Run CeWL against list of URLs contained in urls.txt, write to file out.txt
ruby wordsmith.rb -i urls.txt -m -o out.txt
Source: https://github.com/skahwah/




