GoSpider
GoSpider – Fast web spider wrote in Go
Features
- Fast web crawling
- Brute force and parse sitemap.xml
- Parse robots.txt
- Generate and verify link from JavaScript files
- Link Finder
- Find AWS-S3 from response source
- Find subdomains from response source
- Get URLs from Wayback Machine, Common Crawl, Virus Total, Alien Vault
- Format output easy to Grep
- Support Burp input
- Crawl multiple sites in parallel
- Random mobile/web User-Agent
Changelog v1.1.6
- Refactor and fixes some bugs.
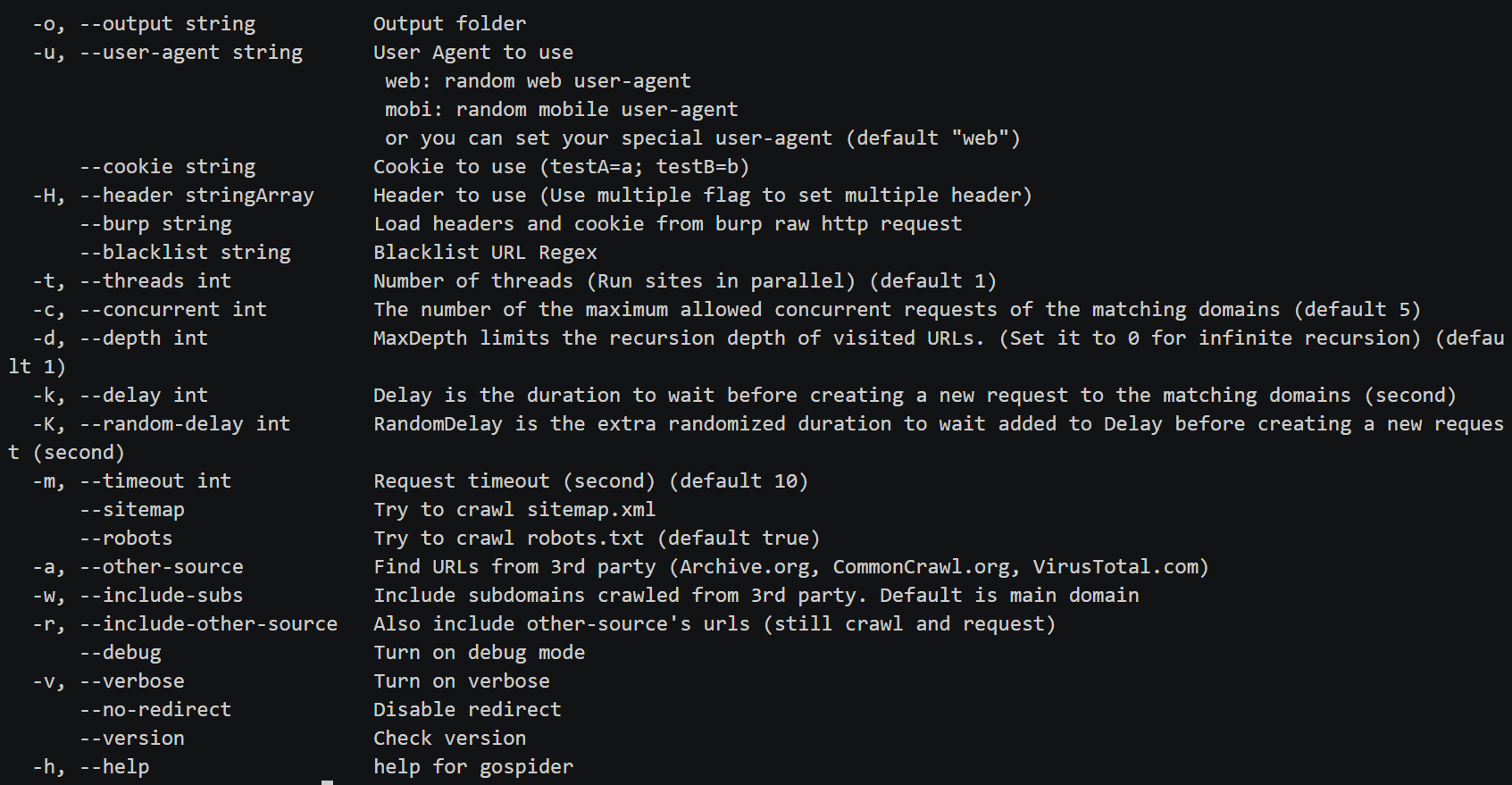
Use
Example commands
Run with a single site
gospider -s "https://google.com/" -o output -c 10 -d 1
Run with site list
gospider -S sites.txt -o output -c 10 -d 1
Run with 20 sites at the same time with 10 bot each site
gospider -S sites.txt -o output -c 10 -d 1 -t 20
Also get URLs from 3rd party (Archive.org, CommonCrawl.org, VirusTotal.com, AlienVault.com)
gospider -s "https://google.com/" -o output -c 10 -d 1 --other-source
Also get URLs from 3rd party (Archive.org, CommonCrawl.org, VirusTotal.com, AlienVault.com) and include subdomains
gospider -s "https://google.com/" -o output -c 10 -d 1 --other-source --include-subs
Use custom header/cookies
Blacklist url/file extension.
P/s: gospider blacklisted .(jpg|jpeg|gif|css|tif|tiff|png|ttf|woff|woff2|ico) as default
gospider -s “https://google.com/” -o output -c 10 -d 1 –blacklist “.(woff|pdf)”
Download
Copyright (c) 2020 j3ssie
