vast v4.4 releases: network telemetry engine for data-driven security investigations
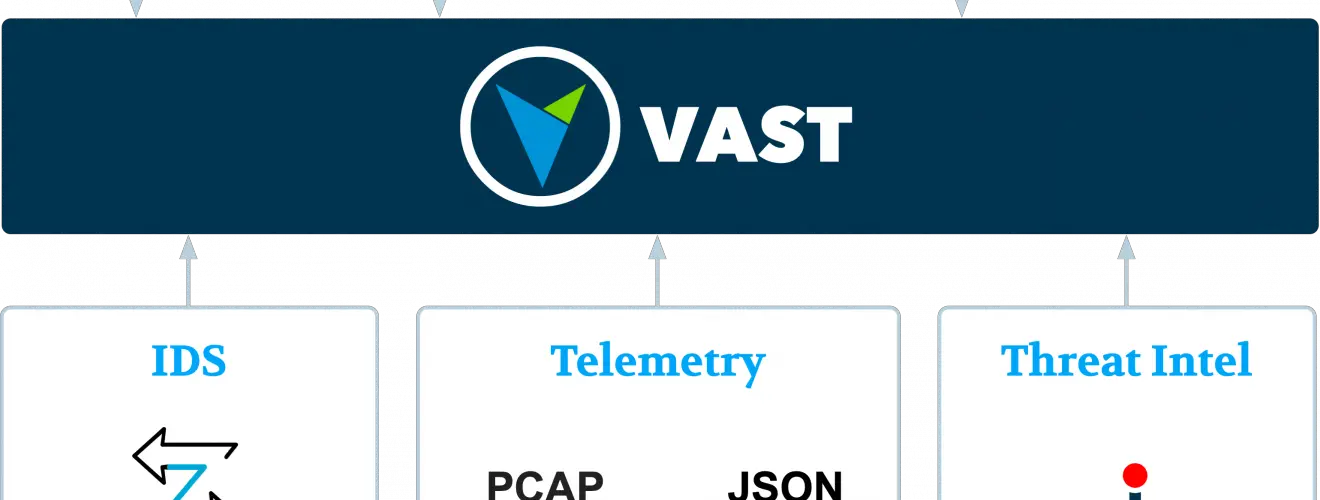
VAST — Visibility Across Space and Time
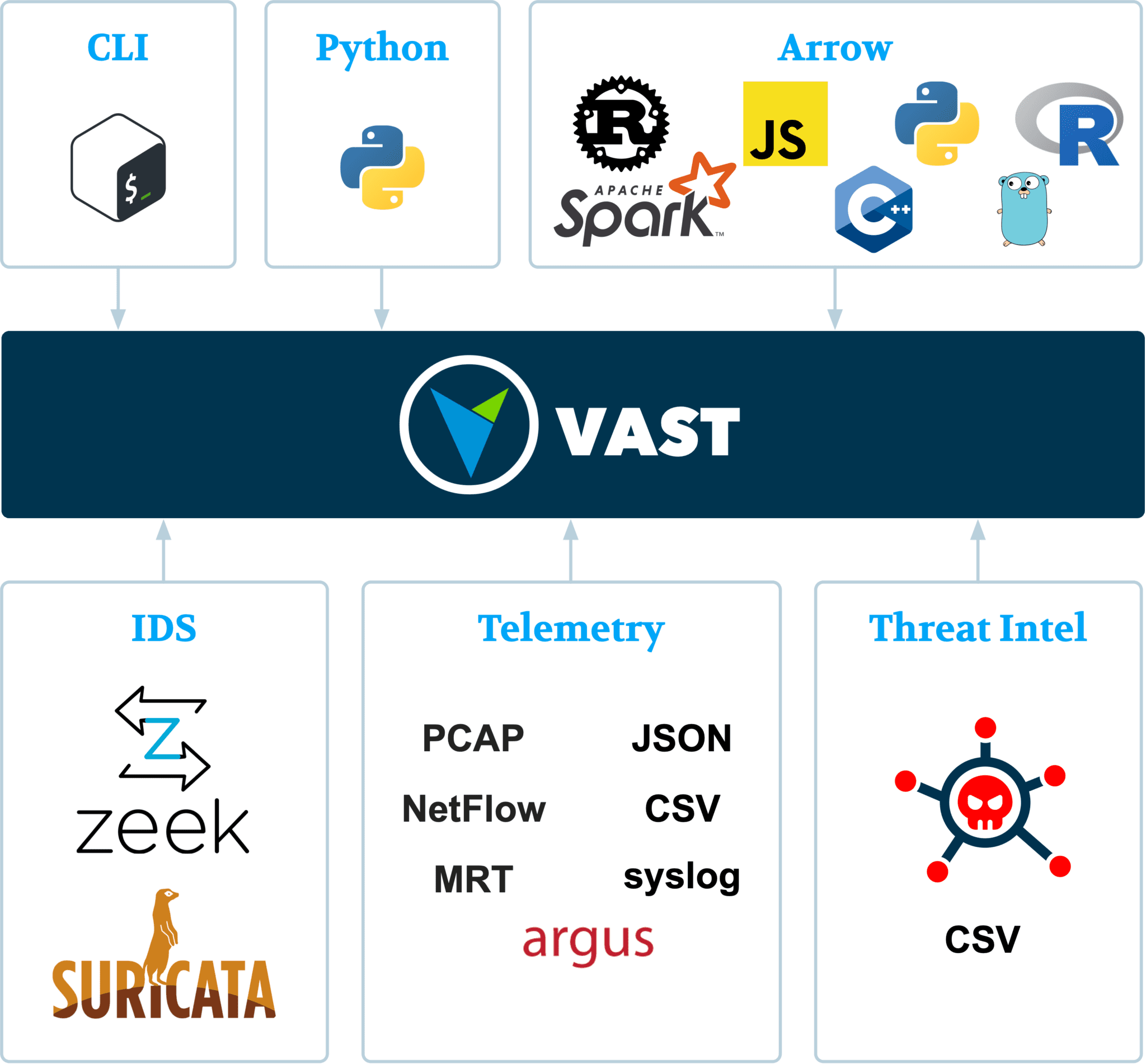
VAST is a network telemetry engine for data-driven security investigations. It ingests high-volume streams of network and logs data, indexes it for later retrieval, and offers several ways to access the data efficiently. The goal is to make network forensics more productive and enable data scientists to tap into the rich world of network event data.
Architecture
Features
- Built for network forensics: VAST is purpose-built for SecOps (incident responders, threat hunters) at the intersection of data science. Security investigations are data investigations, and VAST puts the analyst back in charge, helping to get to the right subset of telemetry for the problem at hand.
- Interactive queries: VAST’s multi-level indexing delivers sub-second response times over the entire telemetry set—perfect for explorative threat-hunting workflows.
- High-throughput streaming: VAST relies on end-to-end streaming to ingest massive amounts of data. Dynamic backpressure ensures that the system does not keel over when stuffing too much data into it.
- Rich Data Model: VAST’s type-rich data model helps to retain domain semantics with a flexible schema and query language. All types support meaningful operations, e.g., IP address support top-k prefix search and containers membership queries. Moreover, VAST’s typed expression syntax allows you to search over fields having a particular type.
- Unfederated data access: VAST defines a portable framing for messages and files to enable access to the data from various platforms. The zero-copy export mechanism makes data sharing with downstream analytics applications incredibly efficient. This empowers data scientists to work on their analytics, as opposed to building tools for parsing and plumbing.
VAST stands for Visibility Across Space and Time to reflect the key benefit for users: make it easy to express temporal and spatial event relationships to illuminate your network analysis.
Changelog v4.4
Changes
- The
stringtype is now restricted to valid UTF-8 strings. Useblobfor arbitrary binary data. #3581 - The new
autostartandautodeleteparameters for the pipeline manager supersede thestart_when_createdandrestart_with_nodeparameters and extend restarting and deletion possibilities for pipelines. #3585
Features
- The new
amqpconnector enables interaction with an AMQP 0-9-1 exchange, supporting working with messages as producer (saver) and consumer (loader). #3546 - The new
completedpipeline state in the pipeline manager shows when a pipeline has finished execution. #3554 - If the node with running pipelines crashes, they will be marked as
failedupon restarting. #3554 - The new
velociraptorsource supports submitting VQL queries to a Velociraptor server. The operator communicates with the server via gRPC using a mutually authenticated and encrypted connection with client certificates. For example,velociraptor -q "select * from pslist()"lists processes and their running binaries. #3556 - The output of
show partitionsincludes a neweventsfield that shows the number of events kept in that partition. E.g., the pipelineshow partitions | summarize events=sum(events) by schemashows the number of events per schema stored at the node. #3580 - The new
blobtype can be used to represent arbitrary binary data. #3581 - The new
ttl_expires_in_nsshows the remaining time to live for a pipeline in the pipeline manager. #3585 - The new
yaraoperator matches Yara rules on byte streams, producing structured events when rules match. #3594 show servesdisplays all currently active serve IDs in the/serveAPI endpoint, showing an overview of active pipelines with an on-demand API. #3596- The
exportoperator now has a--liveoption to continuously emit events as they are imported instead of those that already reside in the database. #3612
Bug Fixes
- Pipelines ending with the
serveoperator no longer incorrectly exit 60 seconds after transferring all events to the/serveendpoint, but rather wait until all events were fetched from the endpoint. #3562 - Shutting down a node immediately after starting it now no longer waits for all partitions to be loaded. #3562
- When using
read json, incomplete objects (e.g., due to truncated files) are now reported as an error instead of silently discarded. #3570 - Having duplicate field names in
zeek-tsvdata no longer causes a crash, but rather errors out gracefully. #3578 - The
csvparsed (or more generally, thexsvparser) now attempts to parse fields in order to infer their types. #3582 - A regression in Tenzir v4.3 caused exports to often consider all partitions as candidates. Pipelines of the form
export | where <expr>now work as expected again and only load relevant partitions from disk. #3599 - The long option
--skip-emptyforread linesnow works as documented. #3599 - The
zeek-tsvparser is now able to handle fields of typesubnetcorrectly. #3606
Install & Use
Copyright (c) 2014, Tenzir GmbH