Google Cloud Abruptly Shuts Down Railway, Sparking Catastrophic Infrastructure Outage
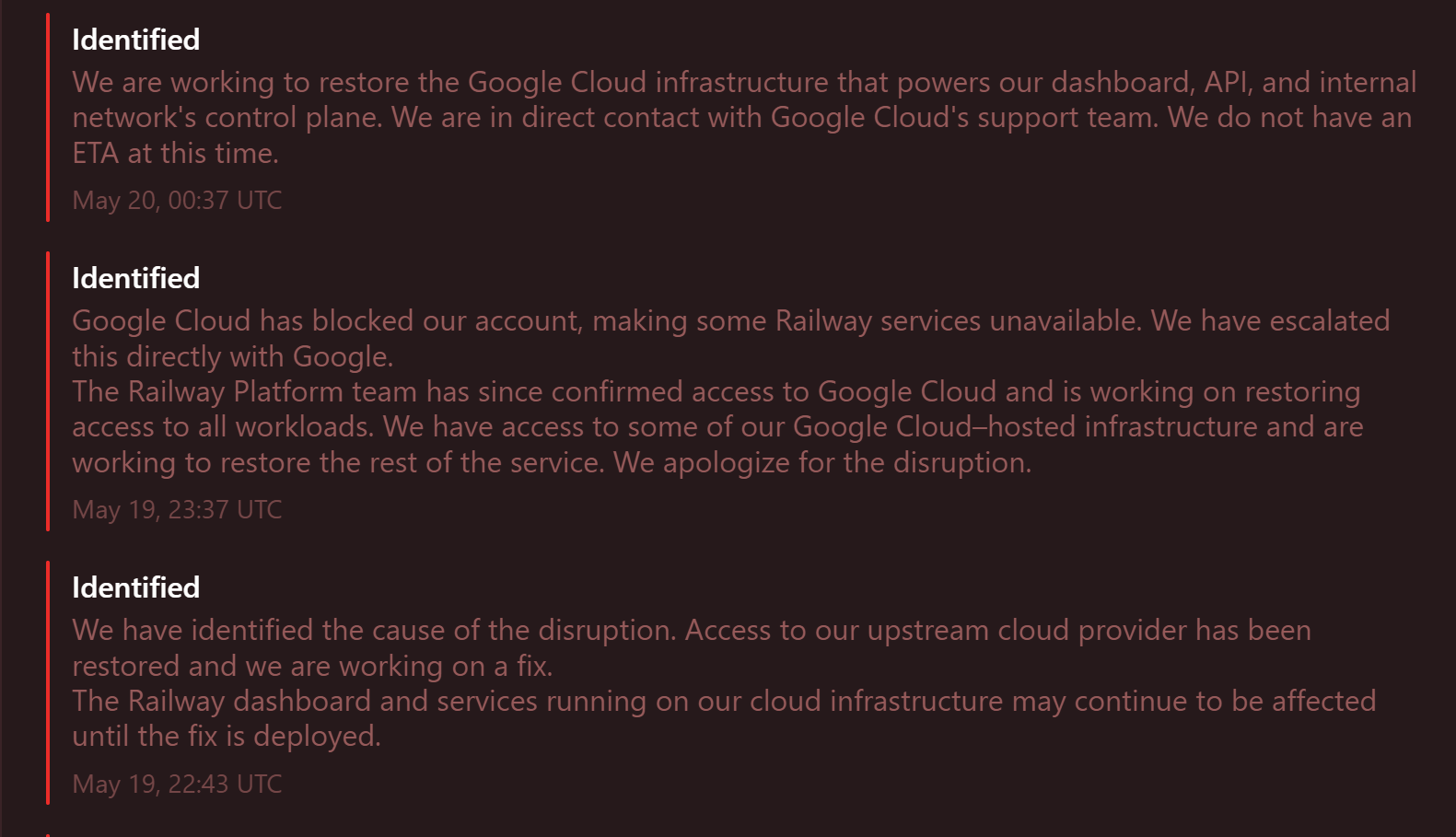
Commencing at 05:29 UTC on May 20, 2026, Railway, a contemporary, developer-centric full-stack intelligent cloud platform, suffered a catastrophic and widespread infrastructure outage. Users were suddenly inundated with a barrage of systemic failures, encompassing the absolute loss of upstream network connectivity, spontaneous session disconnects under severe load, authentication failures, and an inability to access the primary administrative control panels. The sheer velocity and magnitude of this structural collapse left the Railway engineering cohort profoundly astounded.
However, a far more staggering revelation emerged following preliminary forensic triaging: the technical infrastructure team determined that the root cause of the paralysis traced back to an anomaly within their underlying Google Cloud Platform (GCP) architecture. Investigators soon discovered that Google had summarily, and without any prior administrative warning, suspended Railway’s corporate Google Cloud account, instantaneously mothballing the core services tethered to that environment.
To the credit of Railway’s site reliability engineering (SRE) cell, their crisis remediation was remarkably agile. Within thirteen minutes of the initial anomaly detection, the team completed a diagnostic sweep, initiated high-priority escalations with Google’s executive support, and successfully re-secured administrative dominion over their cloud account. Following the restoration of access, the operational team immediately pivoted toward the rigorous task of recycling service daemons and applying structural hotfixes to compromised foundational infrastructure.
Confronted with heavily constrained server resources during the recovery window, the Railway architecture cell implemented an emergency policy temporarily halting all non-enterprise compilation and build queues. This tactical throttling was enforced to prevent a secondary wave of cascading infrastructure collapses induced by host exhaustion, allowing the SRE team to focus strictly on restoring the integrity of their Google Cloud nodes.
The recovery trajectory was further complicated by successive operational hurdles; specifically, the technical team encountered persistent network routing anomalies while attempting to spin up the reclaimed Google Cloud instances, leaving the servers in an unbootable state. Left with no recourse, Railway initiated an expedited request for specialized intervention from Google’s core engineering divisions. At the hour of this dispatch, a comprehensive return to baseline normalcy remains unachieved.
Per the live telemetry published to the official Railway Status architecture matrix, non-enterprise build workflows remain strictly embargoed, and the consumer base may continue to navigate intermittent latency and accessibility regressions. Whether this institutional failure is attributed to a unilateral enforcement action by Google or an internal programmatic oversight within Railway’s infrastructure automation remains unclarified, as the platform has yet to distribute a definitive post-mortem.
This paradigm echoes a notorious historical precedent from 2024, wherein Google Cloud accidentally purged the absolute data footprint of UniSuper, a colossal Australian hyper-annuation fund. In that instance, a Google engineer, while orchestrating a bespoke private cloud deployment, left critical validation configuration variables unpopulated. Consequently, an automated cleanup algorithm executed a destructive erasure of the client’s live production cluster alongside two geographically isolated, cross-regional disaster recovery backups.
Fortunately, UniSuper maintained an autonomous, out-of-band backup architecture independent of the GCP ecosystem, enabling a comprehensive data restoration sequence that ultimately spanned a grueling two-week recovery envelope. Absent that redundant data layer, the failure would have precipitated an institutional catastrophe, given that UniSuper stewards over 125 billion Australian dollars in assets on behalf of more than 620,000 corporate members.
The 2024 incident captured intense global industry scrutiny, ultimately compelling Google to publish a definitive forensic breakdown, characterizing the disaster as a statistically unprecedented, isolated, and highly anomalous event, while pledging to optimize their internal engineering tools to eliminate human-in-the-loop configuration missteps.
Returning to the contemporary Railway suspension crisis, technology architects express hope that this event will serve as a profound wake-up call for the broader software engineering community, mobilizing collective pressure on Google to yield total transparency regarding their automated enforcement algorithms. For modern developers, the realization that mission-critical, foundational infrastructure can be instantaneously neutralized by a unilateral account termination presents a terrifying existential hazard. Should Google fail to proffer an exhaustive, comforting resolution, it may catalyze a massive migration away from Google Cloud by practitioners unwilling to gamble their operational continuity on an unvetted algorithm.
Support Our Threat Intelligence
If you find our CVE report and cybersecurity news helpful, consider supporting our work.
