Image: wavefnx
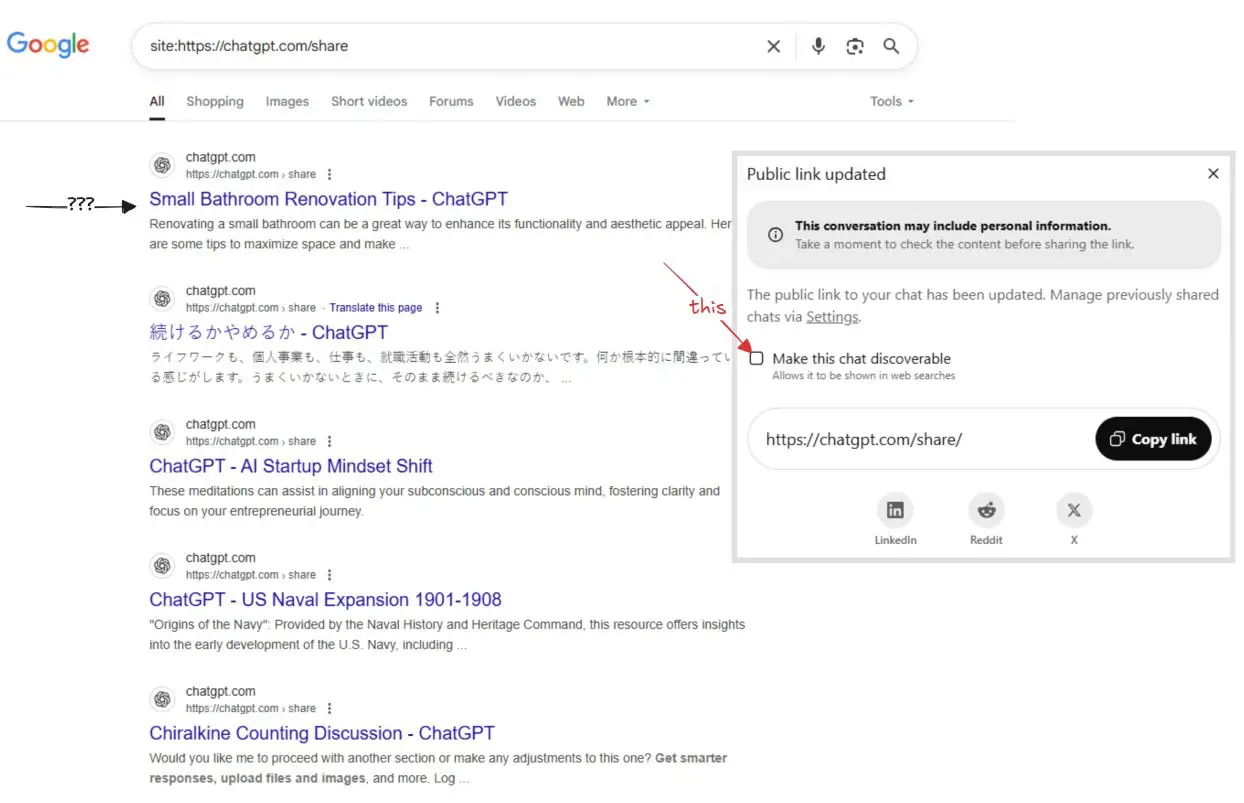
ChatGPT has recently come under fire for testing a feature that allowed search engines to index user conversations. As a result, over 100,000 chat records were made publicly accessible across the internet. Although OpenAI has since collaborated with Google to de-index these links, more than 100,000 remain searchable and accessible through platforms like the Internet Archive and other search engines.
This incident was not the result of a technical bug but rather a grave miscalculation by OpenAI regarding the average user’s level of technical proficiency. Specifically, ChatGPT’s conversation-sharing feature enables users to generate shareable links for their chats, which are typically accessible only to those who possess the link. However, the newly tested feature introduced an option for users to permit search engines to crawl and index these shared conversations. While this option was not selected by default, OpenAI appears to have overestimated users’ understanding of the implications. Despite clear warnings, many users checked the option—likely unaware of what it truly entailed.
Upon discovering the privacy implications, OpenAI swiftly disabled the feature and worked with Google to remove indexed content. Nonetheless, the links themselves remain live and continue to be accessible, meaning that search engines such as Microsoft Bing and archival services like the Internet Archive have already indexed over 100,000 links, which can still be visited directly.
Among the indexed conversations are chats containing highly sensitive material. One such conversation, conducted in Italian, involved a lawyer representing a multinational energy corporation. The company was planning to construct a dam and hydroelectric plant in the Amazon rainforest. The proposed site, however, was home to a small indigenous Amazonian community. In the conversation, the lawyer sought ChatGPT’s advice on how to exploit the local inhabitants, stating that the indigenous people were unaware of the land’s value and lacked understanding of market mechanisms. The lawyer asked ChatGPT for negotiation strategies to secure the land at the lowest possible cost.
Although the transcript is believed to still reside within the Internet Archive, fact-checking expert Henk van Ess, who first discovered the link, declined to make it public—citing privacy concerns. The conversation contained enough detail to potentially identify the energy company and even the individual lawyer involved.
From a privacy standpoint, van Ess opted not to reveal the link, though he noted that locating it within the Internet Archive would not be particularly difficult. Since the Archive had already captured a snapshot, even deletion of the original conversation by the lawyer within ChatGPT would be futile.
Notably, the Internet Archive stated that OpenAI had not contacted them with a takedown request. Had such a request been made, the Archive indicated it would have complied. However, OpenAI appears to have limited its mitigation efforts to Google Search, neglecting other search engines and archival services.
Related Posts:
- ChatGPT Exposed: OpenAI’s Sharing Feature Leaks Private Conversations to Google Search
- Google Unleashes “Search Live”: Converse with AI in Real-Time for Mobile Search
- Gemini Advanced Remembers: Google’s AI Gets a Memory Boost
Support Our Threat Intelligence
If you find our CVE report and cybersecurity news helpful, consider supporting our work.
