AI Crawlers Deluge Wikimedia Commons, Consuming Over 65% of High-Cost Bandwidth

The Wikimedia Commons project, an integral part of the Wikipedia ecosystem, is currently under siege by an onslaught of AI-powered web crawlers. Hosting over 144 million images, videos, and other media files, Wikimedia has become a rich reservoir targeted by artificial intelligence companies seeking to harvest its vast multimedia trove for training large-scale AI models.
These AI crawlers—numerous and operating in patterns that diverge significantly from human browsing behavior—are placing an immense burden on Wikimedia’s infrastructure, devouring costly bandwidth and straining its resources. In response, the Wikimedia Foundation is initiating countermeasures to stem the relentless drain imposed by this non-human traffic.
In a recent blog post, Wikimedia revealed that since January 2024, bandwidth usage related to multimedia downloads has surged by 50%. This spike is not attributed to human readers but to automated agents—bots systematically scraping openly licensed content from Wikimedia Commons for AI training purposes.
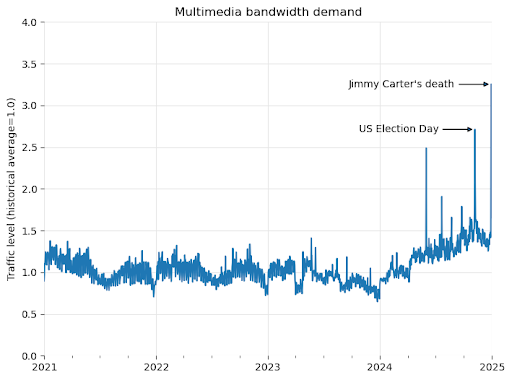
Wikimedia’s infrastructure is engineered to withstand sudden surges in legitimate user traffic during high-profile events. However, the magnitude and persistence of the crawler traffic present unprecedented challenges, introducing escalating risk and operational cost.
The ongoing, steady rise in baseline bandwidth consumption since early 2024 shows no signs of abating. This persistent elevation compromises Wikimedia’s capacity to absorb genuine traffic spikes, diverting significant time and resources toward managing traffic from non-human agents.
To ensure fast access for users worldwide, Wikimedia operates a global network of data centers. Frequently accessed content is cached at regional nodes nearest to users. Conversely, rarely requested files are not cached and must be retrieved directly from core data centers when accessed—typically the case with niche or less popular content.
Whereas human users gravitate toward commonly viewed topics, AI bots indiscriminately scrape massive volumes of content, including obscure and seldom-accessed files. As a result, their requests disproportionately bypass regional caches and target the core infrastructure.
Bandwidth at these central data centers is prohibitively expensive. During a recent system migration, the Wikimedia team discovered that 65% of core bandwidth consumption stemmed from bot traffic, leaving human usage at a mere 35%. The scale of this automated load is so substantial it has begun to degrade the browsing experience for legitimate users.
In its annual planning draft, Wikimedia emphasized the importance of WE5—responsible stewardship of its infrastructure. While its content remains free and openly accessible, the underlying infrastructure is not. Faced with unsustainable demand, the Foundation asserts that decisive action is now required to reestablish a healthy balance—one that safeguards the time, contributions, and experience of Wikimedia’s editors and readers from being eroded by unchecked AI harvesting.
Related Posts:
- Google Requires JavaScript for Search: Bots and Crawlers Impacted
- Reddit Restricts Search Indexing, Google Gets Exclusive Pass
- Fighting AI Crawlers: Cloudflare Unleashes the AI Labyrinth
Support Our Threat Intelligence
If you find our CVE report and cybersecurity news helpful, consider supporting our work.
