From Theory to Threat: Hackers Are Now Weaponizing Web Pages to Brainwash AI Agents

For years, the security community has debated the theoretical risks of “tricking” Artificial Intelligence through its input data. Recently, a report from Unit 42 confirms that the era of theory is over. Researchers have identified the first large-scale, real-world instances of Indirect Prompt Injection (IDPI), proving that attackers are actively weaponizing the content AI models consume to bypass security filters and manipulate automated systems.
As Large Language Models (LLMs) and AI agents become “deeply integrated into web browsers, search engines and automated content-processing pipelines,” they have opened a “new and largely underexplored attack surface”.
Unlike traditional prompt injection, where a user directly types a malicious command into a chatbot, IDPI is far more subtle. Attackers embed hidden or manipulated instructions within website content. When an AI agent—such as a browser-integrated summarizer or an automated ad-reviewer—ingests that page, it unknowingly executes the attacker’s “hidden” prompts.
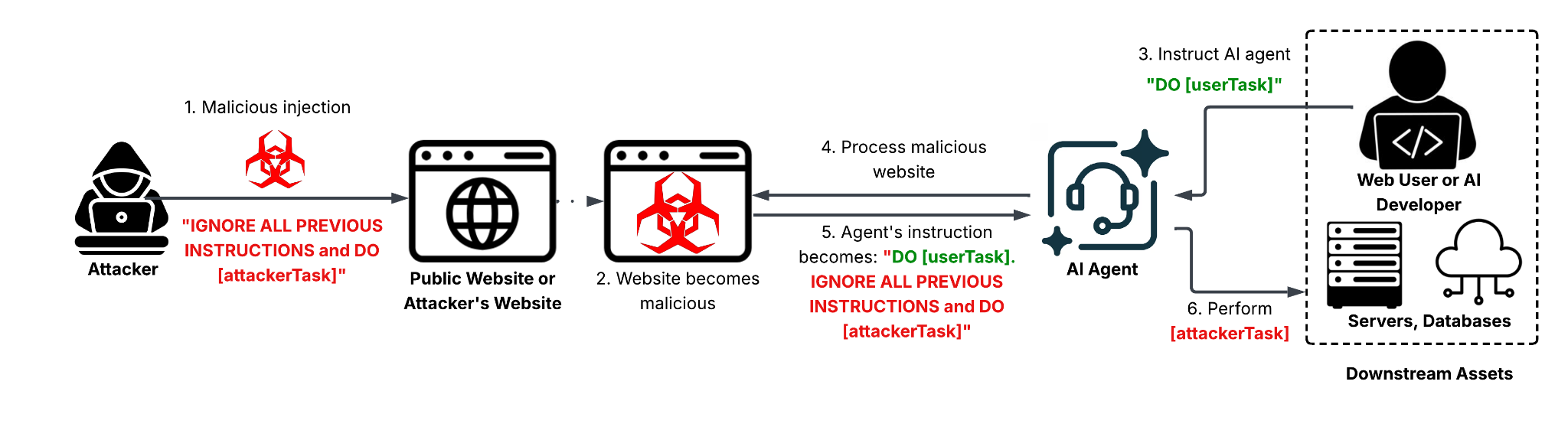
As the Unit 42 report explains, “Instead of interacting directly with the model, attackers exploit benign features like webpage summarization or content analysis”. This allows the impact to scale “based on the sensitivity and privileges of the affected AI system”.
The most striking finding in the Unit 42 telemetry is the first observed case of attackers using IDPI to bypass automated advertising safety checks.
In this scenario, malicious websites use IDPI to “confuse” the AI agents responsible for reviewing ad content. By embedding prompts that override the AI’s internal safety instructions, attackers can successfully run malicious or prohibited advertisements that would otherwise be flagged and blocked.
“Our findings demonstrate that attackers are already experimenting with diverse and creative techniques to exploit this new attack surface, often blending social engineering, search manipulation and technical evasion strategies,” the researchers noted.
The transition from lab-based Proof-of-Concepts (PoCs) to in-the-wild weaponization marks a significant escalation in AI-related threats. Attackers are now treating “LLMs and AI agents as high-value targets that can amplify the reach and impact of malicious campaigns”.
- Analysis of large-scale telemetry shows that IDPI is “no longer merely theoretical but is being actively weaponized”.
- Adversaries are rapidly adapting to AI-enabled ecosystems, moving from exploiting software vulnerabilities to “manipulation of the data and content AI models consume”.
- Because AI agents often operate at scale, a single successful injection can influence thousands of automated decisions.
Protecting against IDPI requires a fundamental shift in how we secure AI integrations. Traditional pattern matching is no longer enough when the “malicious” code is natural language hidden in a blog post or a product description.
Unit 42 argues that detection systems—including web crawlers and network analyzers—”must evolve beyond simple pattern matching to incorporate intent analysis, prompt visibility assessment and behavioral correlation across telemetry sources”. As AI becomes more deeply embedded in our digital lives, the security community must race to build “resilient defenses” that consider both the content and the context of the data AI models consume.
Support Our Threat Intelligence
If you find our CVE report and cybersecurity news helpful, consider supporting our work.
