Google Unleashes Gemma 3n: Breakthrough On-Device Multimodal AI for Smartphones & Laptops

Google has recently unveiled Gemma 3n, a groundbreaking open-source, on-device multimodal AI model designed to deliver the performance of high-end models directly to smartphones, tablets, and laptops—bringing multimodal capabilities once exclusive to the cloud into the hands of everyday users. The Gemma 3n models are now available via Hugging Face, accompanied by comprehensive technical documentation and development guides.
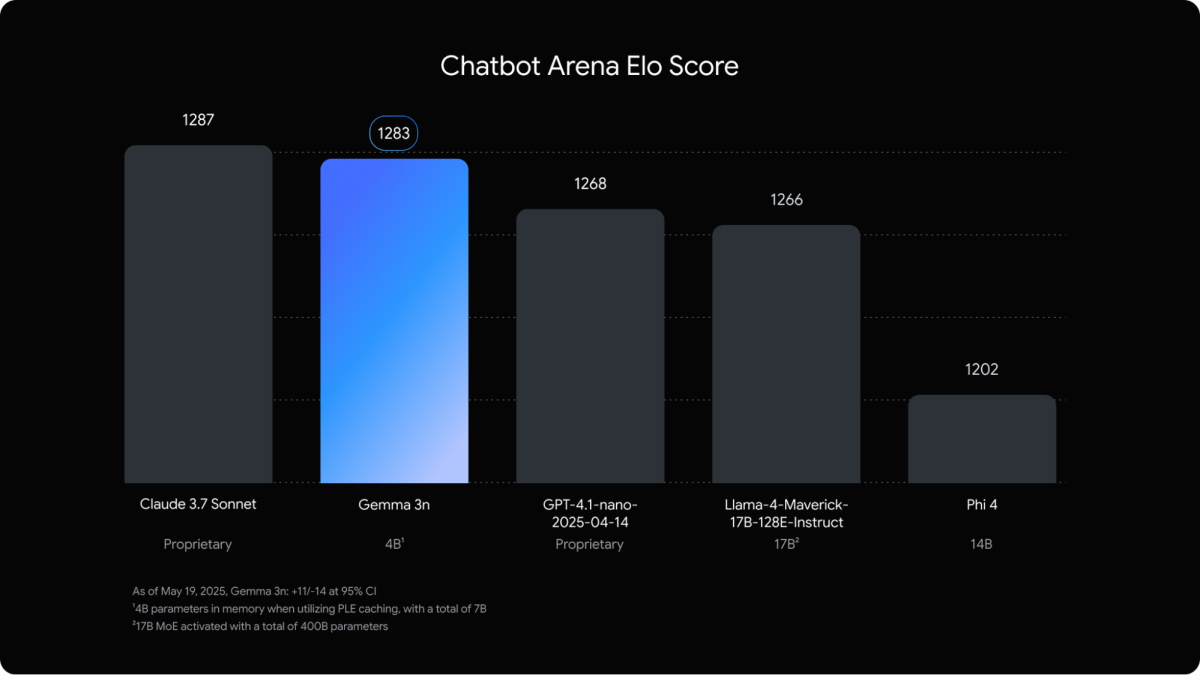
The most striking feature of Gemma 3n lies in its native ability to process input from images, audio, video, and text, while generating natural language responses. The initial release includes two variants—E2B (approximately 2 billion effective parameters) and E4B (around 4 billion)—offering remarkable computational efficiency that rivals traditional models with 5 to 8 billion parameters.
Gemma 3n is built upon the innovative MatFormer (Matryoshka Transformer) architecture, which emphasizes Elastic Inference, enabling developers to dynamically adjust model scale through a Mix-n-Match approach. This allows the model to be customized according to device constraints, with seamless execution on devices equipped with as little as 2GB or 3GB of memory.
To further enhance efficiency, Gemma 3n introduces PLE (Per-Layer Embedding), a novel memory architecture that offloads non-critical parameters to the CPU and RAM, while reserving key Transformer weights for the AI accelerator. This drastically improves memory utilization and allows even entry-level devices to perform near-cloud-grade inference.
To better handle lengthy text and multimedia streams, Gemma 3n incorporates a next-generation KV Cache Sharing mechanism, significantly reducing response latency for initial token generation—crucial for real-time video and speech applications. The speech module features a state-of-the-art encoder derived from Google USM, supporting both Automatic Speech Recognition (ASR) and Automatic Speech Translation (AST). The first release includes multilingual support for translations from English to Spanish, French, Italian, and Portuguese.
In the realm of visual processing, Gemma 3n integrates the all-new MobileNet-V5 vision encoder, capable of handling input resolutions from 256 to 768 pixels. Built upon the MobileNet-V4 foundation with advanced multi-scale fusion, the encoder achieves 13x acceleration and 4x reduction in memory usage on the Google Pixel Edge TPU, while also outperforming undistilled SoViT models in accuracy.
As a milestone in Google’s broader AI on Device strategy, Gemma 3n not only cements its leadership in multimodal model technology but also sets the stage for a future where intelligent computing is native to mobile devices. The Gemma series is expected to continue evolving toward smaller models with greater performance, unlocking new frontiers in on-device artificial intelligence.
Related Posts:
- Google AI Search: Gemini Expands to Search Labs
- Google Boosts Real-Time Protection Against Scams and Malware on Android Devices
- GPT-4 Retiring: GPT-4o Takes Over in ChatGPT
- Google AI Edge Gallery: Unleash On-Device AI Power on Your Android (and Soon iOS!)
Support Our Threat Intelligence
If you find our CVE report and cybersecurity news helpful, consider supporting our work.
