Hardware Autonomy: Meta’s “High Velocity” Roadmap to Deploy Four AI Chips by 2027
Confronting the colossal daily computational demands of AI generation and recommendation from its billions of users, Meta has resolved to seize its hardware destiny with its own hands. The conglomerate unveiled the latest developmental roadmap for its bespoke silicon, the Meta Training and Inference Accelerator (MTIA). Diverging from the orthodox one-to-two-year product life cycles of traditional semiconductor fabricators, Meta has proclaimed its intent to systematically deploy a quartet of nascent chip generations—comprising the MTIA 300, 400, 450, and 500—within a mere biennial span, culminating in 2027.
Through an ingenious “modular chiplet” architecture and an unwavering “Inference-First” stratagem, Meta endeavors to forge a proprietary path—one harmonizing superlative performance with profound cost-efficiency—amidst a prevailing landscape heavily tethered to commercial GPUs from titans such as NVIDIA.
Within the traditional semiconductor dominion, the engineering and launch of a nascent AI processor customarily demands a gestation period of one to two years. Nevertheless, the evolutionary velocity of artificial intelligence models has long since eclipsed the orthodox cadences of hardware development. Lest its hardware languish behind its software, Meta has adopted a fiercely radical “High Velocity” iterational stratagem—compressing the deployment cycle of nascent silicon to approximately once every six months. This staggering celerity, akin to agile software development, owes its triumph to a profoundly modular design philosophy.
Spanning from the MTIA 400 through the 500, Meta has uniformly integrated identical chassis, rack, and network infrastructures, adhering strictly to the Open Compute Project (OCP) standards. This decrees that successive generations of silicon can be seamlessly swapped into extant server racks via a drop-in methodology, thereby drastically truncating the temporal void between semiconductor fabrication and data center operationalization.
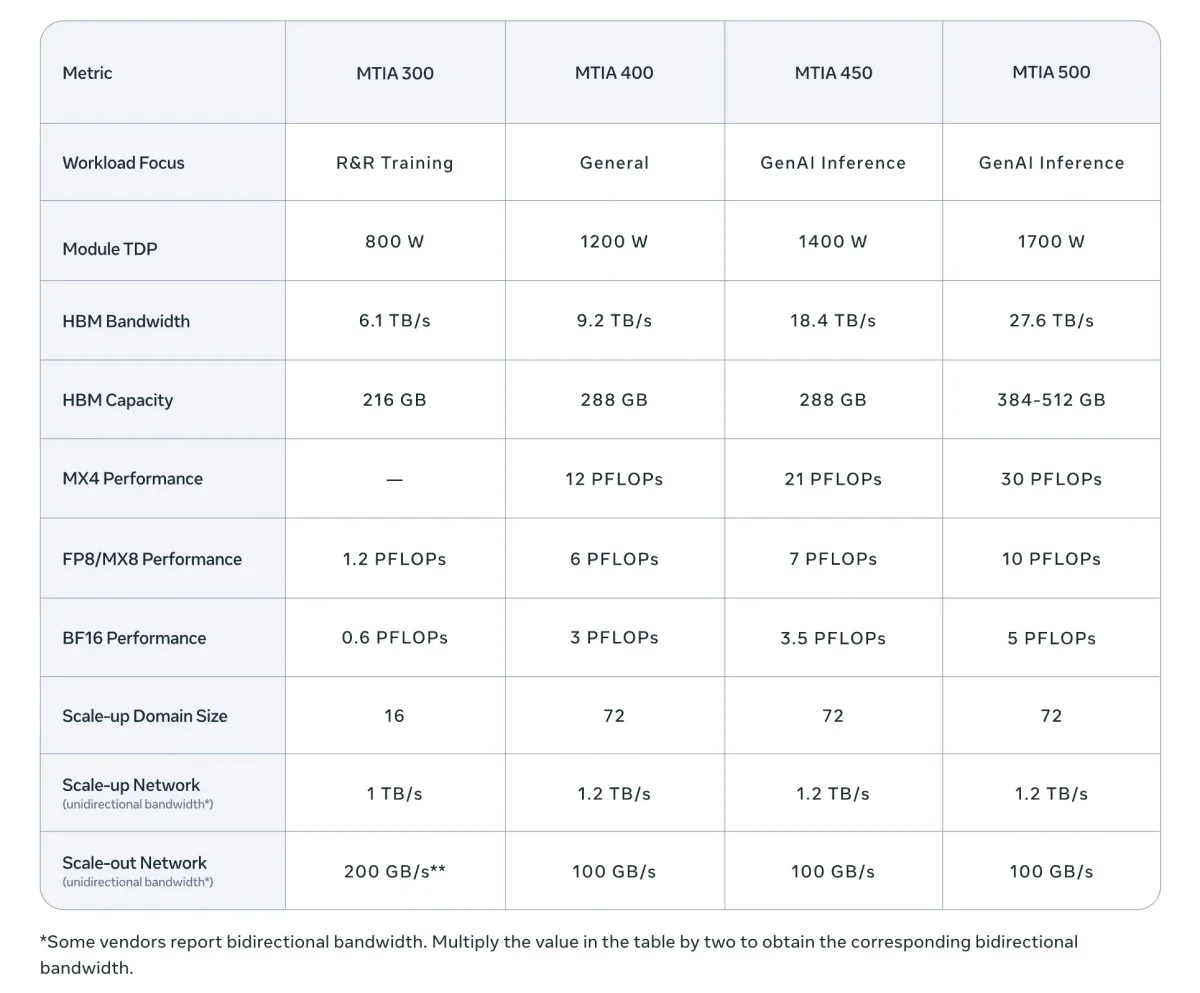
According to the chronologies and specifications promulgated by Meta, these four distinct MTIA processors are each entrusted with strategic mandates across sequential phases:
- MTIA 300 (Currently in Mass Production): Serving as the cornerstone of formidable cost-performance, this iteration is preeminently optimized for Meta’s orthodox “Ranking and Recommendation” (R&R) matrices, concurrently laying the foundational network and communication architecture for subsequent GenAI silicon.
- MTIA 400 (Imminent Deployment): This embodies Meta’s inaugural offering equipped to directly rival top-tier commercial silicon, such as the NVIDIA lineage. Beyond sustaining recommendation computations, it profoundly fortifies GenAI support capabilities; its FP8 computational prowess surges by 400% compared to its antecedent, whilst High Bandwidth Memory (HBM) bandwidth escalates by 51%.
- MTIA 450 (Projected Early 2027): Bespoke for “GenAI Inference.” Given that the inference celerity of Large Language Models (LLMs) is exquisitely dependent upon memory bandwidth, the MTIA 450 directly doubles the HBM bandwidth and introduces low-precision data formats specifically architected for inference (such as MX4), achieving a performance that eclipses contemporary leading commercial artifacts.
- MTIA 500 (Projected 2027): Pushing boundaries even further, this iteration builds upon the 450 by elevating HBM bandwidth by an additional 50% and MX4 computational might by 43%. It embraces a more sophisticated 2×2 compute chiplet configuration, realizing the orchestration of maximal AI inference capacity at an absolute minimum expenditure.
Presently, the overarching majority of mainstream GPUs dominating the market are architected for the immensely computationally intensive “pre-training” of colossal generative AI models, only subsequently being downscaled for inference execution. Meta perceives this paradigm as profoundly fiscally imprudent.
Consequently, the MTIA 450 and 500 embrace a diametrically opposed “Inference-First” stratagem. From their very inception, they are optimized for decode generation and Mixture-of-Experts (MoE) architectures, ensuring that when confronting the daily deluge of billions of users summoning the Meta AI assistant, the computational expenditure per unit is ruthlessly suppressed to its absolute nadir.
More crucially, as the progenitor of PyTorch—the globe’s most venerated AI framework—Meta has endowed the MTIA with native PyTorch support from day one. Developers are liberated from the arduous task of rewriting code, enabling models to migrate seamlessly between commercial GPUs and MTIA architectures, thereby entirely eradicating the agonizing friction typically associated with the induction of nascent hardware.
By unequivocally laying its cards on the table regarding the MTIA design roadmap for the ensuing biennium, Meta is effectively telegraphing a singular doctrine: procuring exorbitant silicon to train models is permissible, but leveraging premium GPUs to service non-paying patrons is entirely out of the question.
The training of a monolithic model akin to Llama 4, or the forthcoming Llama 5, undeniably necessitates tens of thousands of zenith-tier commercial GPUs—which fundamentally explains why Meta remains a colossal patron of NVIDIA. Yet, training represents a singular, ephemeral expenditure. Once the model ascends to production, confronting the daily, staggering tsunami of inference requests from an excess of three billion active denizens across Facebook, Instagram, and WhatsApp constitutes an abyssal, never-ending chasm of operational costs.
Should Meta be compelled to surrender exorbitant “GPU hardware and power consumption taxes” for every snippet of text generated or every Reel recommended, the conglomerate’s gross margins would be precipitously devoured. The genesis and light-speed iteration of the MTIA lineage is, in its essence, the formidable hardware moat Meta has erected to fiercely safeguard its profitability paradigm.
Through the profound synthesis of open-source software (PyTorch, vLLM) with open-hardware architectures (OCP), Meta is not merely emancipating itself from the shackles of a singular hardware purveyor; it is unequivocally demonstrating to the industry that, within specific, hyper-scale application arenas, bespoke Application-Specific Integrated Circuits (ASICs) will prove vastly more potent and profoundly more efficient than pedestrian GPUs.
Support Our Threat Intelligence
If you find our CVE report and cybersecurity news helpful, consider supporting our work.
