Red Hat has recently unveiled an open-source initiative named llm-d, designed to address the most critical demand of the generative AI era: large-scale inference.
The llm-d project is a collaborative effort launched by founding contributors CoreWeave, Google Cloud, IBM Research, and NVIDIA, with support from industry leaders including AMD, Cisco, Hugging Face, Intel, Lambda, and Mistral AI, as well as academic institutions such as the University of California, Berkeley, and the University of Chicago. The project’s overarching ambition is to make generative AI applications in production as ubiquitous and foundational as Linux.
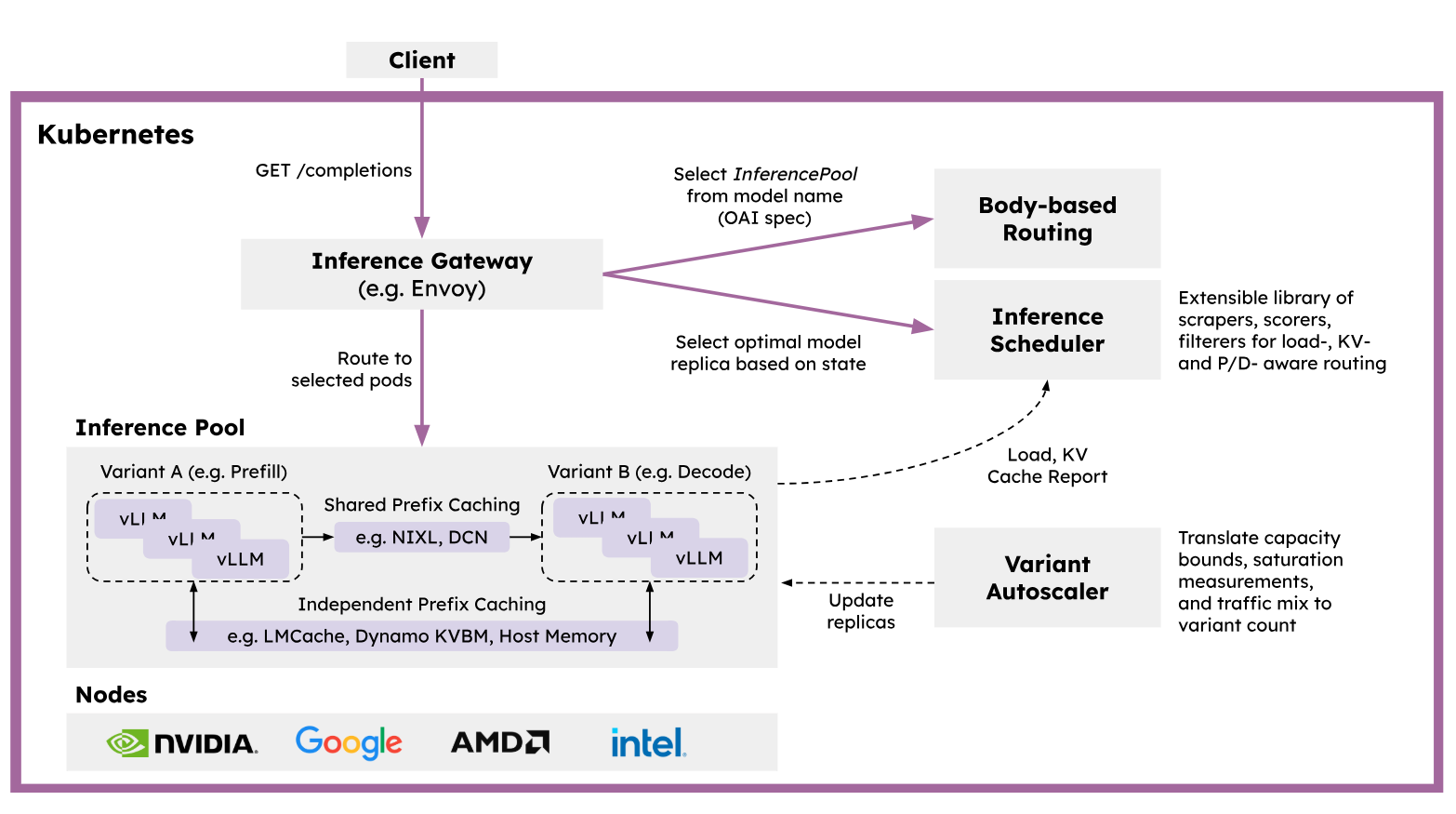
Leveraging cutting-edge large-scale inference technologies, llm-d is architected natively for Kubernetes, built upon distributed inference via vLLM, and powered by intelligent, AI-aware network routing. It delivers a robust cloud-native infrastructure for large language model (LLM) inference, engineered to meet the most demanding service-level objectives (SLOs) in enterprise environments.
Brian Stevens, Senior Vice President and Chief AI Officer at Red Hat, remarked: “The launch of the llm-d community, supported by a consortium of AI pioneers, signals a pivotal moment in our pursuit to scale generative AI inference. It represents one of the key challenges organizations must overcome to unlock the broader potential of AI. By harnessing vLLM’s innovative architecture and Kubernetes’ proven capabilities, llm-d empowers enterprises to achieve scalable, distributed, and high-performance AI inference seamlessly across hybrid cloud environments—supporting any model, on any accelerator, in any cloud.”
In response to the growing complexity of AI infrastructure, Red Hat and its partners introduced llm-d as a forward-looking initiative to enhance vLLM beyond the constraints of single-server deployments and unleash the full potential of production-grade inference at scale. Through Kubernetes’ mature scheduling capabilities, llm-d seamlessly integrates advanced inference workloads into existing IT environments, enabling IT teams to meet the diverse demands of mission-critical workloads on a unified platform—while maximizing efficiency and significantly lowering the total cost of ownership (TCO) associated with high-performance AI accelerators.
Key Features of llm-d Include:
- vLLM, which has quickly become the open source de facto standard inference server, providing day 0 model support for emerging frontier models, and support for a broad list of accelerators, now including Google Cloud Tensor Processor Units (TPUs).
- Prefill and Decode Disaggregation to separate the input context and token generation phases of AI into discrete operations, where they can then be distributed across multiple servers.
- KV (key-value) Cache Offloading, based on LMCache, shifts the memory burden of the KV cache from GPU memory to more cost-efficient and abundant standard storage, like CPU memory or network storage.
- Kubernetes-powered clusters and controllers for more efficient scheduling of compute and storage resources as workload demands fluctuate, while maintaining performance and lower latency.
- AI-Aware Network Routing for scheduling incoming requests to the servers and accelerators that are most likely to have hot caches of past inference calculations.
- High-performance communication APIs for faster and more efficient data transfer between servers, with support for NVIDIA Inference Xfer Library (NIXL).
This ambitious open-source effort has garnered strong backing from a coalition of leading generative AI model providers, accelerator innovators, and top-tier AI cloud platforms. Founding contributors CoreWeave, Google Cloud, IBM Research, and NVIDIA are joined by key collaborators AMD, Cisco, Hugging Face, Intel, Lambda, and Mistral AI—reflecting a deep, industry-wide commitment to building the future of scalable LLM services. Academic founding supporters include the Sky Computing Lab at UC Berkeley (originators of vLLM) and the LMCache Lab at the University of Chicago (creators of LMCache).
With its steadfast commitment to open collaboration, Red Hat recognizes that a vibrant, accessible community is essential in the fast-evolving landscape of generative AI inference. Red Hat will continue to actively cultivate the llm-d ecosystem—fostering inclusivity for new participants, nurturing innovation, and driving the sustained growth of the project.
Related Posts:
- CVE-2024-0087: NVIDIA Releases Security Patch for Critical Flaw in Triton Inference Server
- Red Hat & AMD Deepen AI Partnership: Optimizing AI and Virtualization
- PoC Published for Critical Nvidia Triton Inference Server Vulnerabilities
- Critical CVSS 9.8 RCE Flaw in vLLM Exposes AI Hosts to Remote Attacks
- Critical Remote Code Execution Vulnerability in vLLM via Mooncake Integration
Support Our Threat Intelligence
If you find our CVE report and cybersecurity news helpful, consider supporting our work.
