Uscrapper: powerful OSINT webscraper for personal data collection
Uscrapper
Introducing Uscrapper 2.0, A powerful OSINT web scrapper that allows users to extract various personal information from a website. It leverages web scraping techniques and regular expressions to extract email addresses, social media links, author names, geolocations, phone numbers, and usernames from both hyperlinked and non-hyperlinked sources on the webpage, supports multithreading to make this process faster, Uscrapper 2.0 is equipped with advanced Anti-web scrapping bypassing modules and supports web crawling to scrape from various sublinks within the same domain. The tool also provides an option to generate a report containing the extracted details.
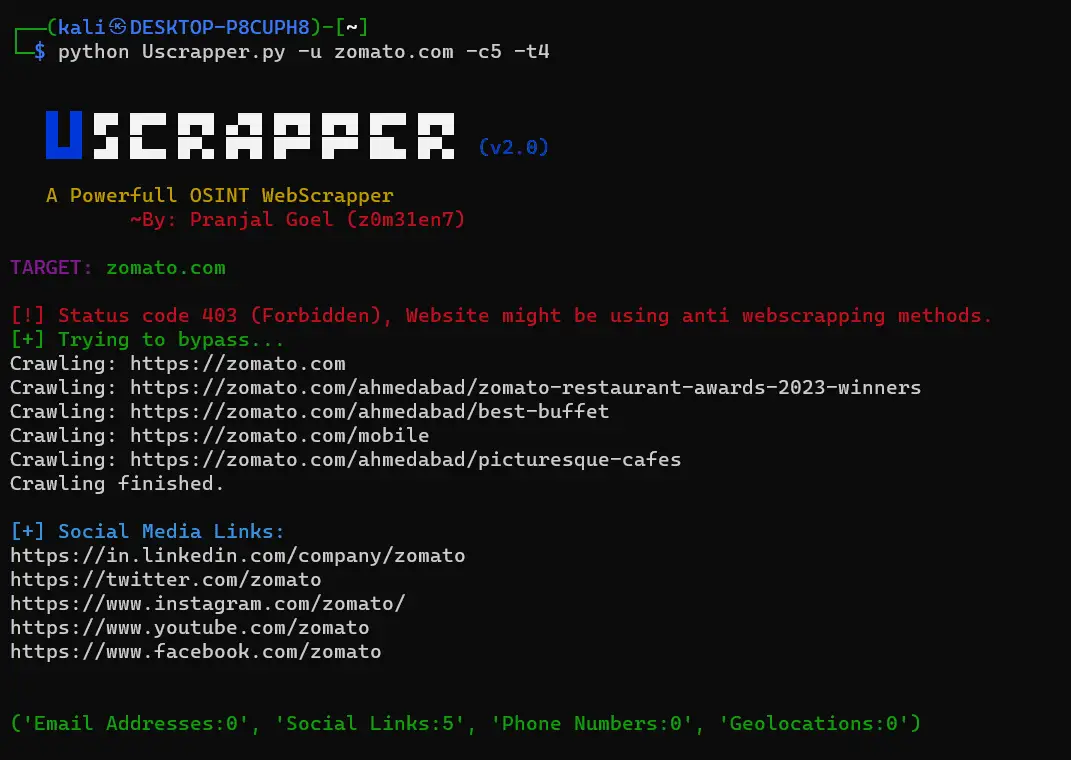
Extracted Details:
Uscrapper extracts the following details from the provided website:
- Email Addresses: Displays email addresses found on the website.
- Social Media Links: Displays links to various social media platforms found on the website.
- Author Names: Displays the names of authors associated with the website.
- Geolocations: Displays geolocation information associated with the website.
- Non-Hyperlinked Details: Displays non-hyperlinked details found on the website including email addresses phone numbers and usernames.
Installation
git clone https://github.com/z0m31en7/Uscrapper.git
cd Uscrapper/install/
chmod +x ./install.sh && ./install.sh #For Unix/Linux systems
Use
To run Uscrapper, use the following command-line syntax:
Arguments:
- -h, –help: Show the help message and exit.
- -u URL, –url URL: Specify the URL of the website to extract details from.
- -c INT, –crawl INT: Specify the number of links to crawl
- -t INT, –threads INT: Specify the number of threads to use while crawling and scraping.
- -O, –generate-report: Generate a report file containing the extracted details.
- -ns, –nonstrict: Display non-strict usernames during extraction.
Note:
-
Uscrapper relies on web scraping techniques to extract information from websites. Make sure to use it responsibly and in compliance with the website’s terms of service and applicable laws.
-
The accuracy and completeness of the extracted details depend on the structure and content of the website being analyzed.
-
To bypass some Anti-Webscrapping methods we have used selenium which can make the overall process slower.
Copyright (c) 2023 Pranjal Goel
Source: https://github.com/z0m31en7/